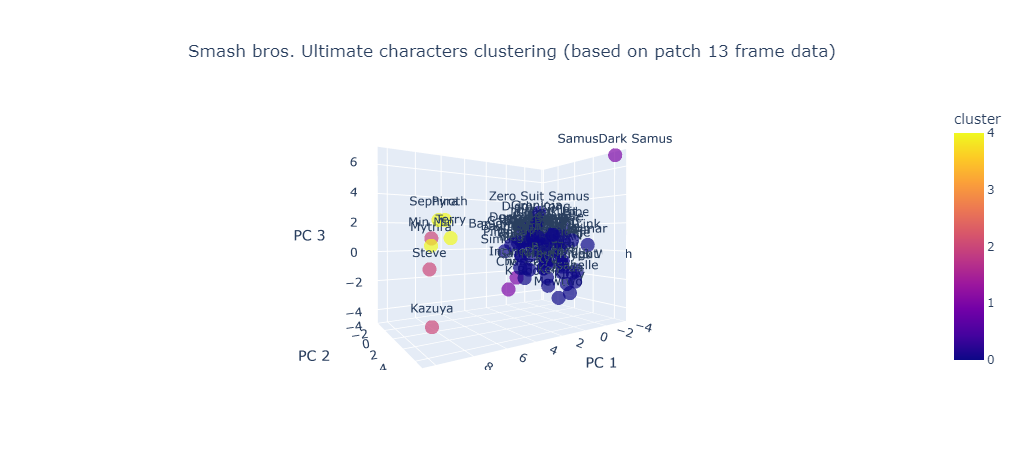
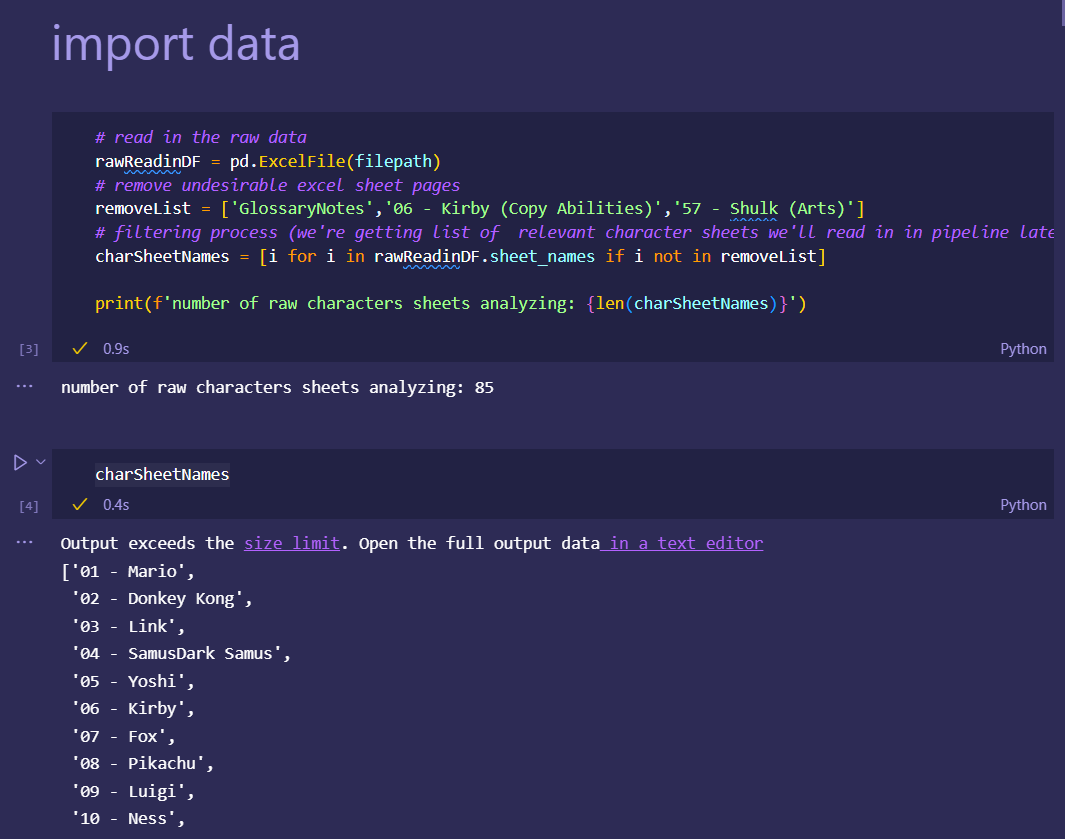
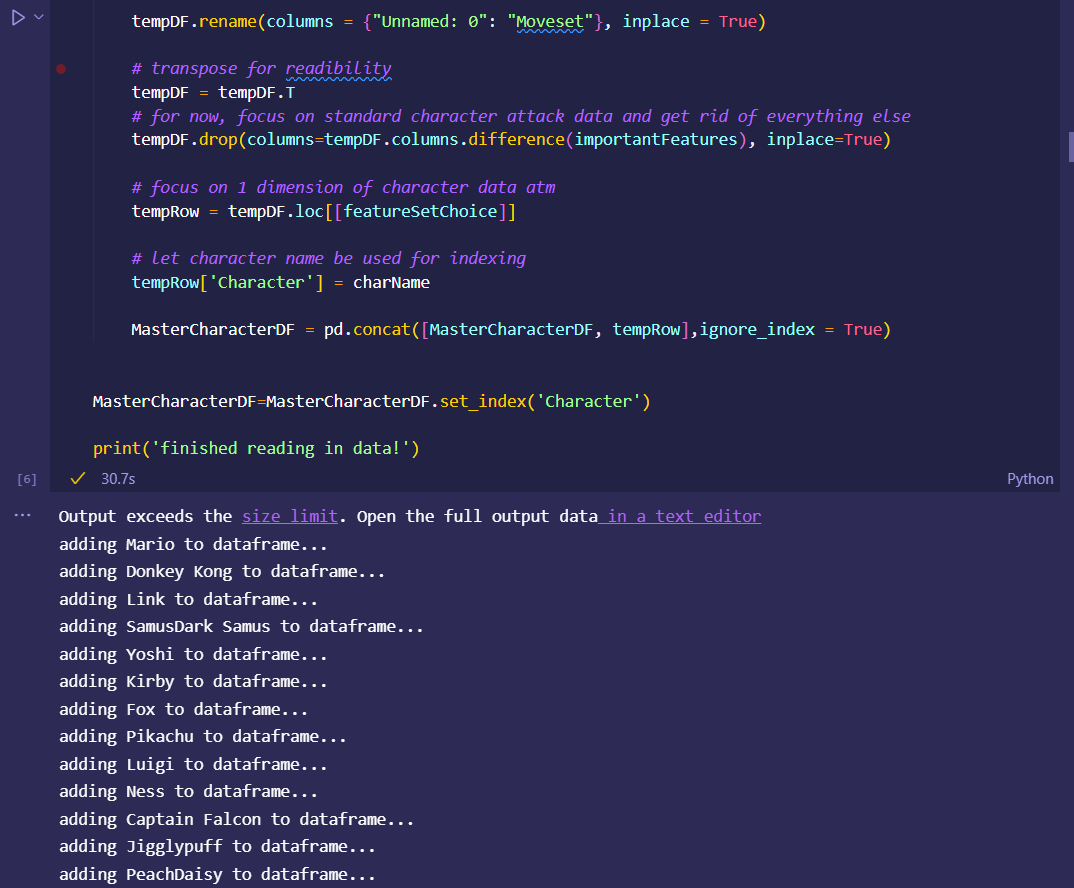
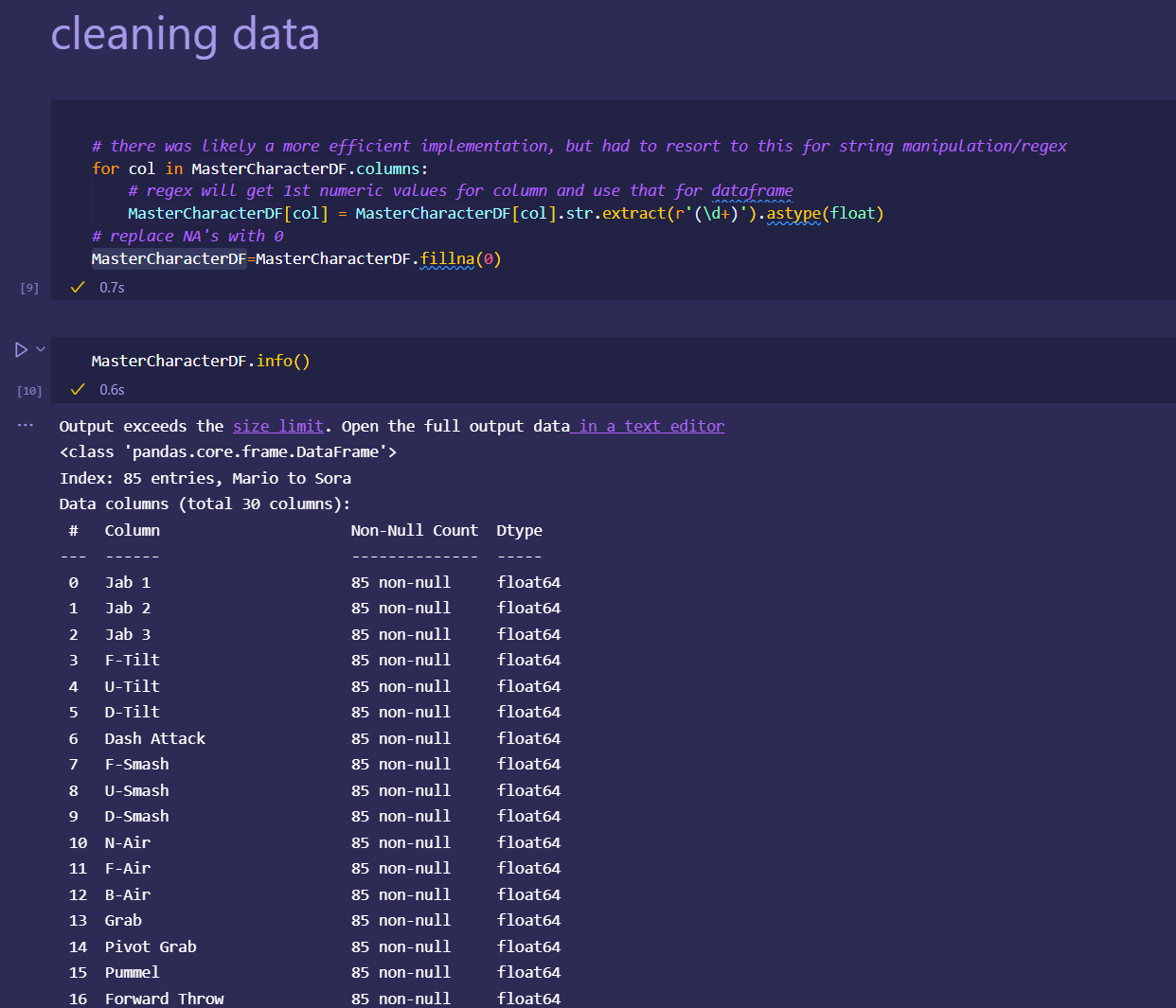
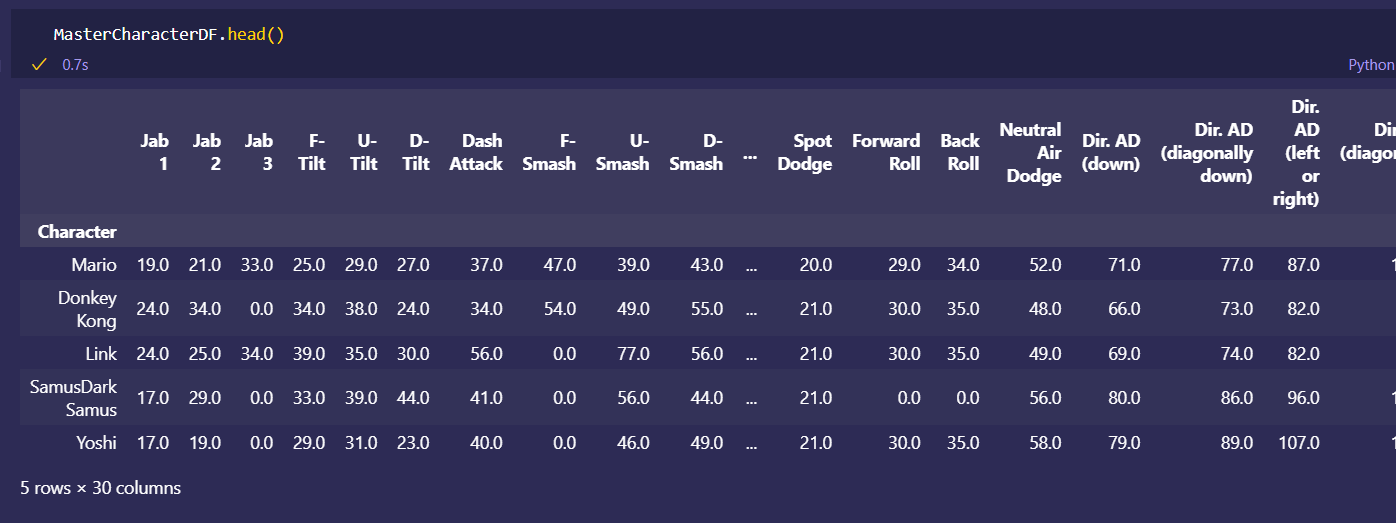
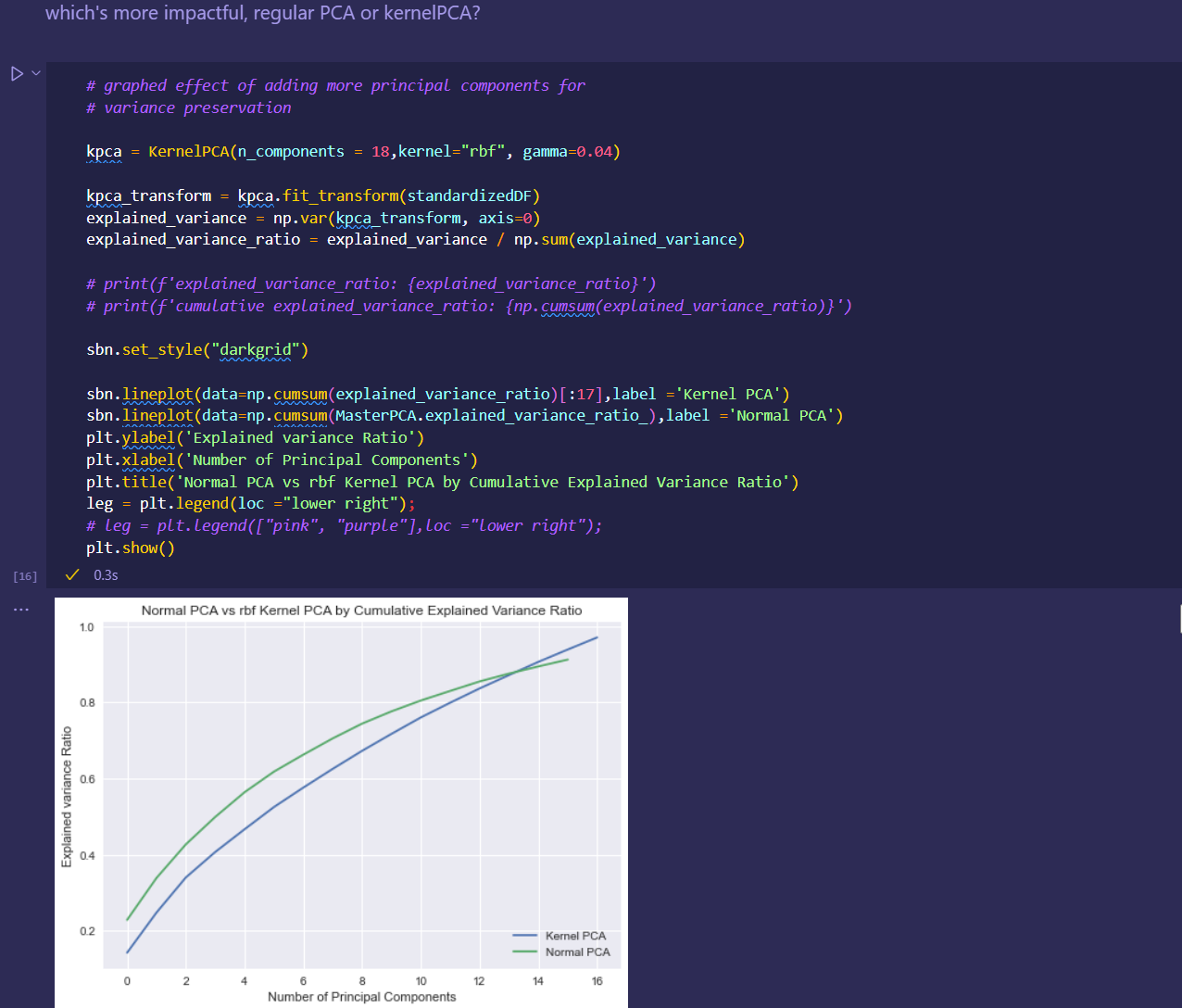
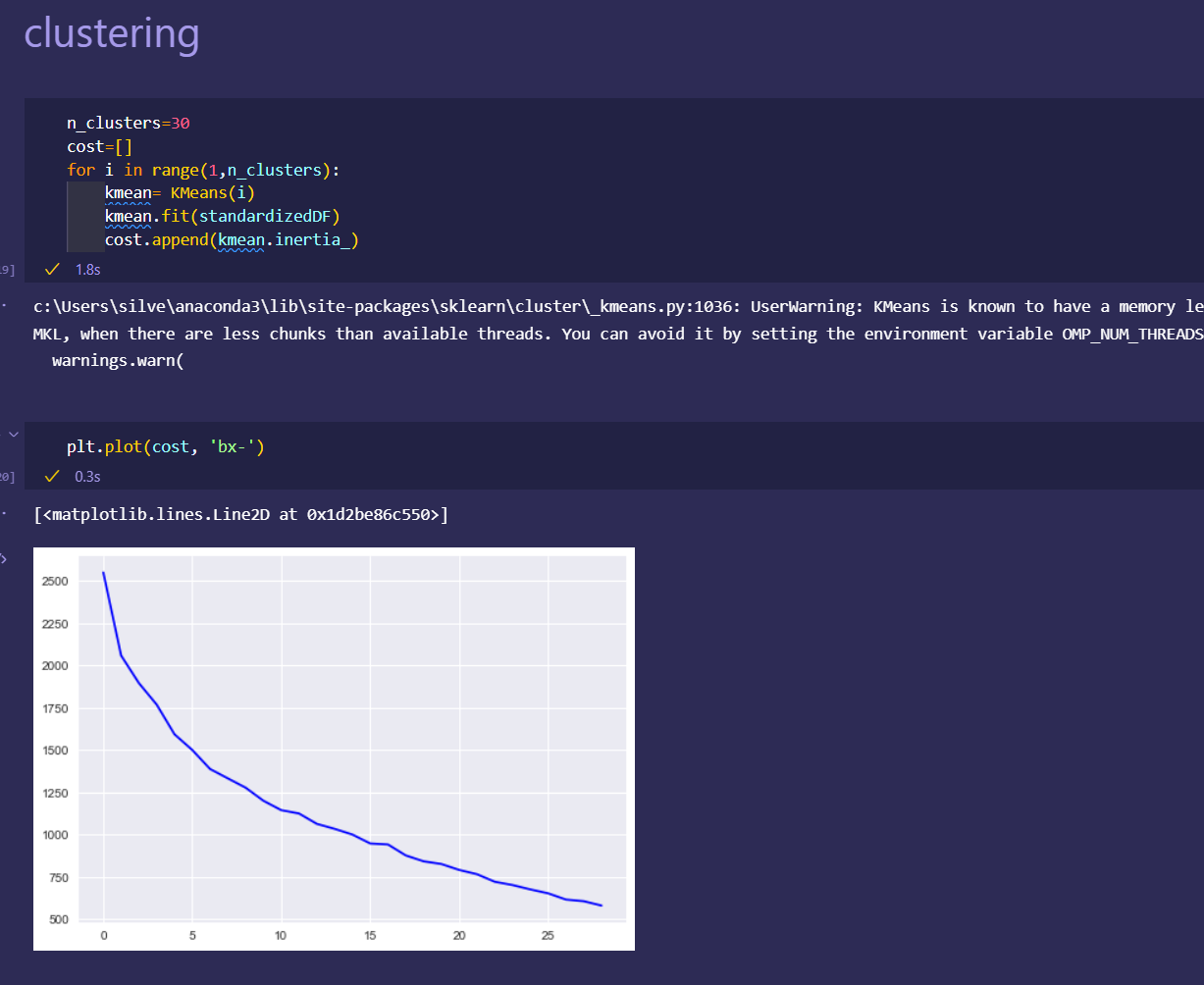
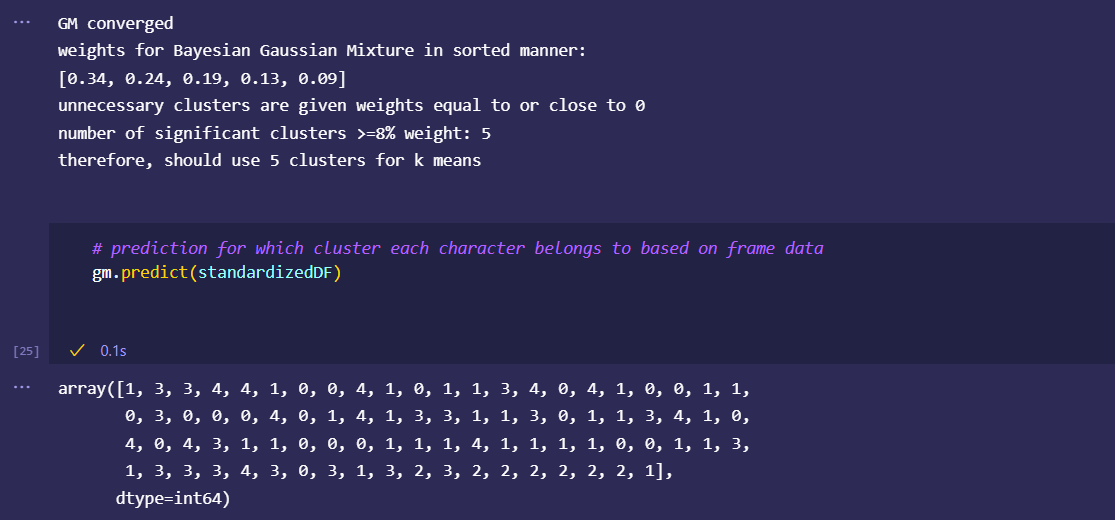
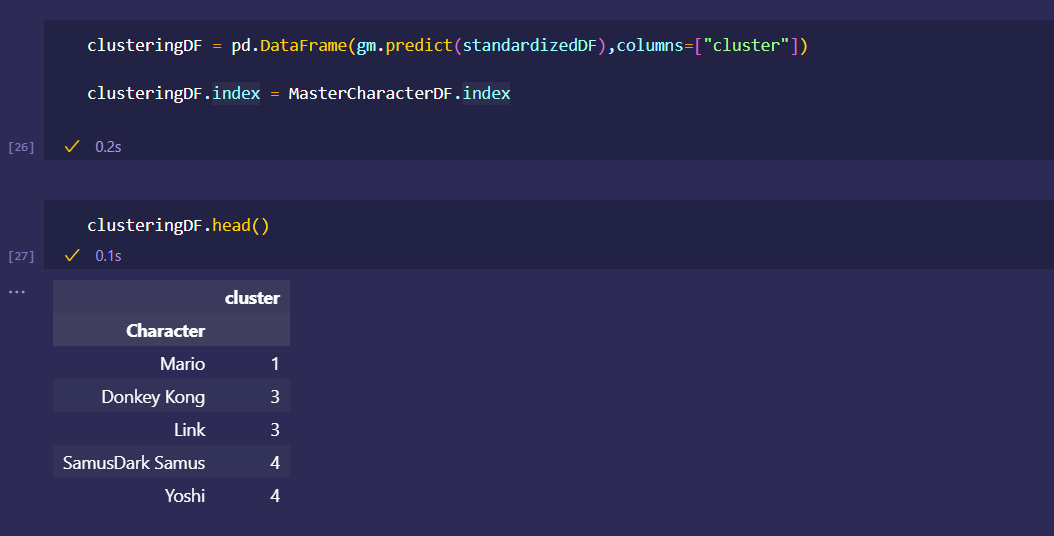
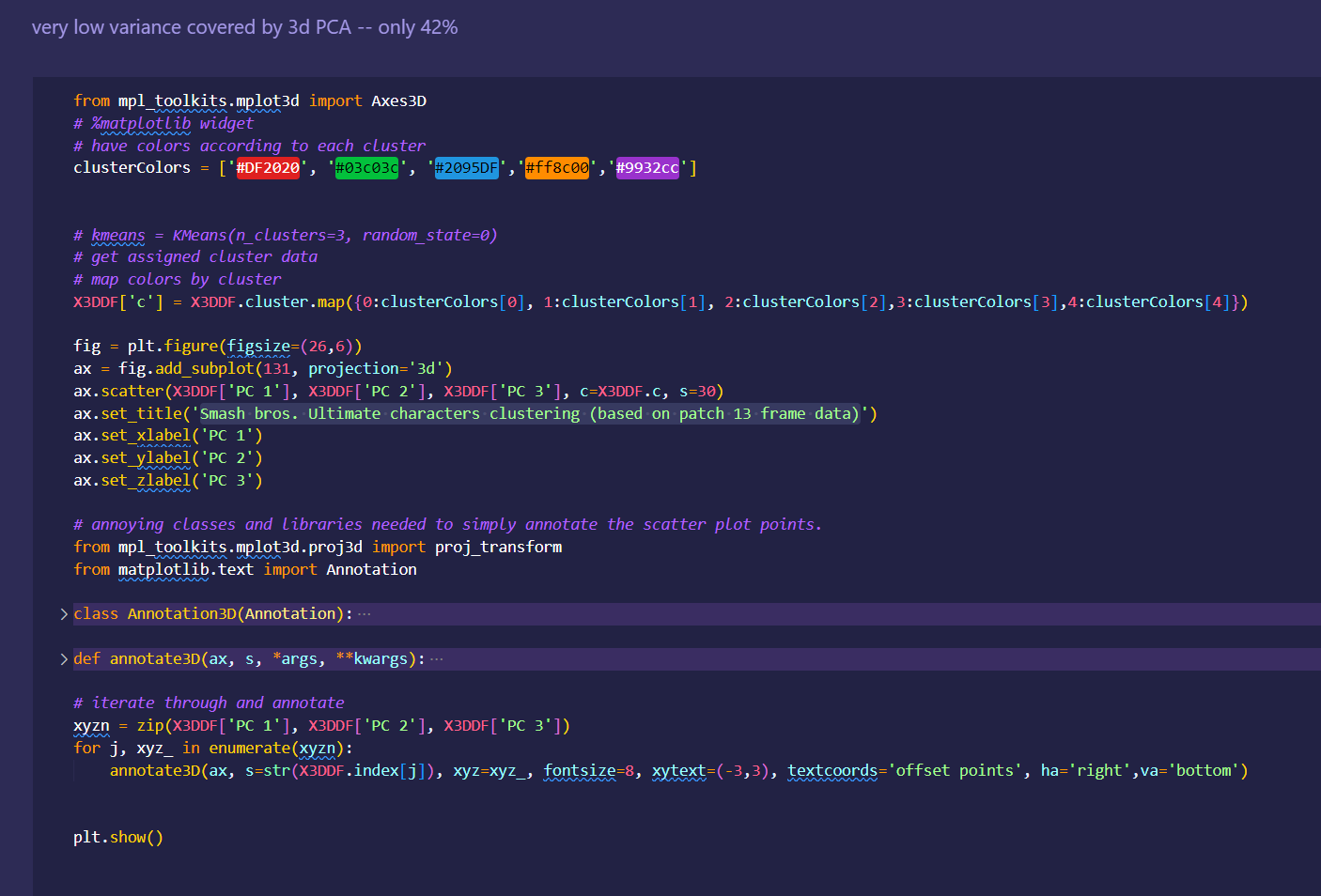
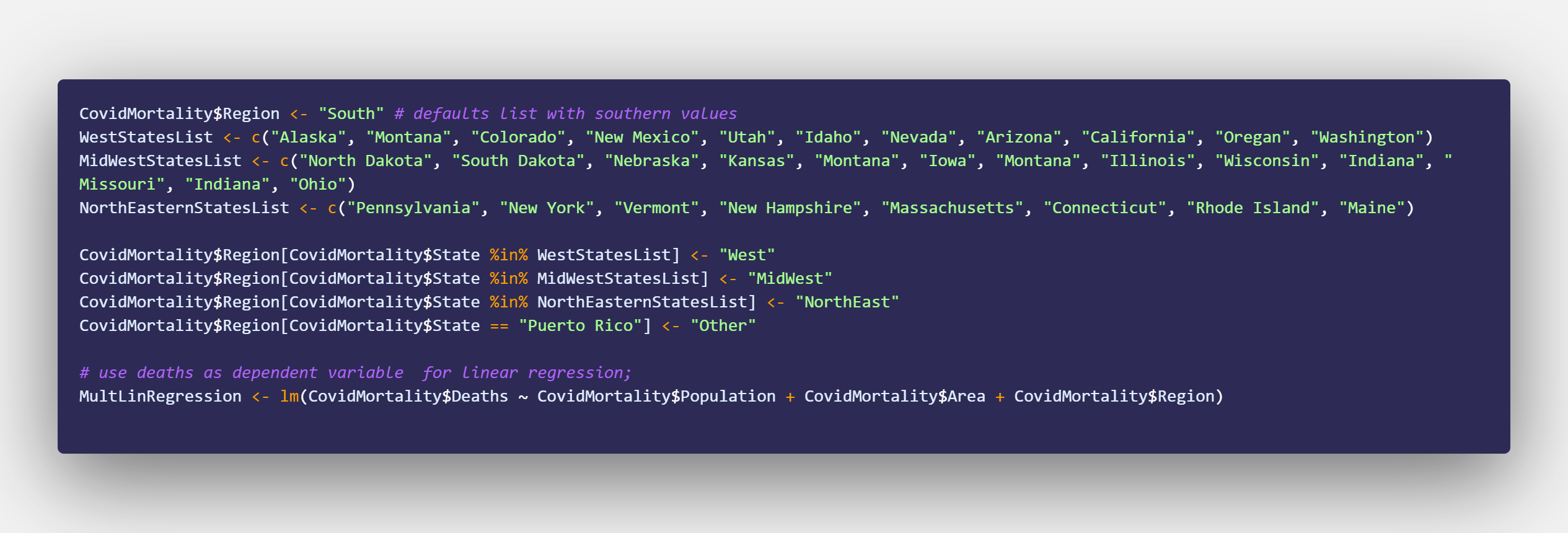
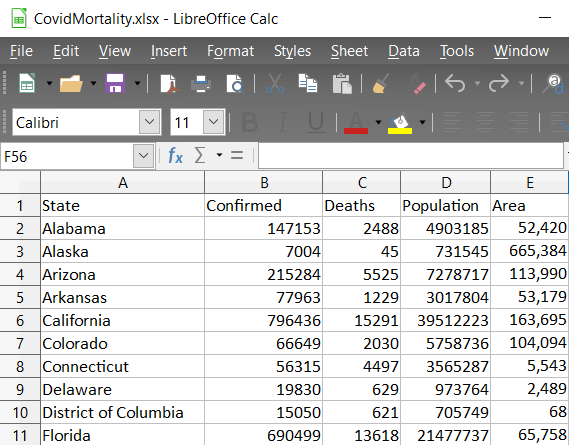
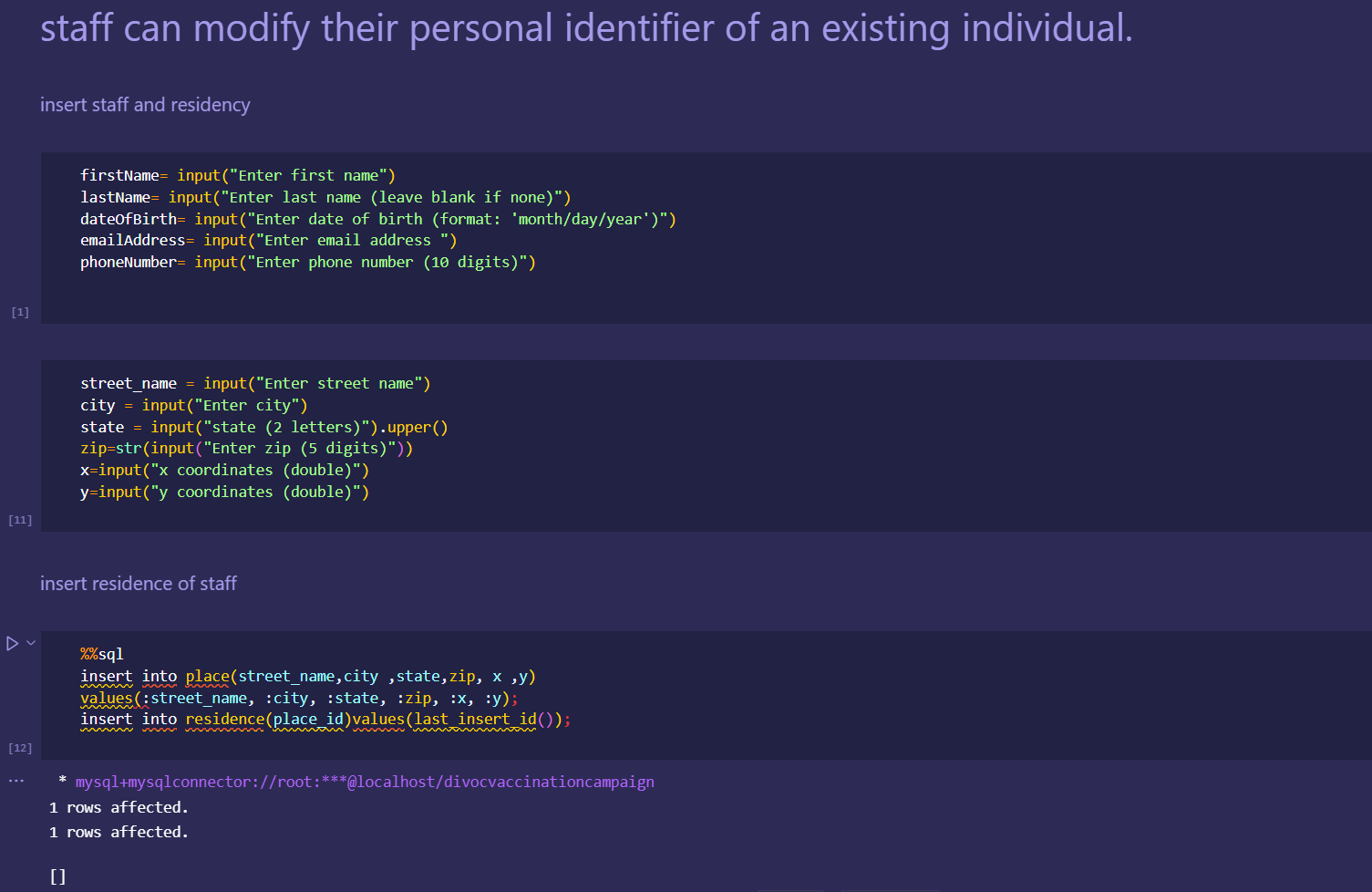
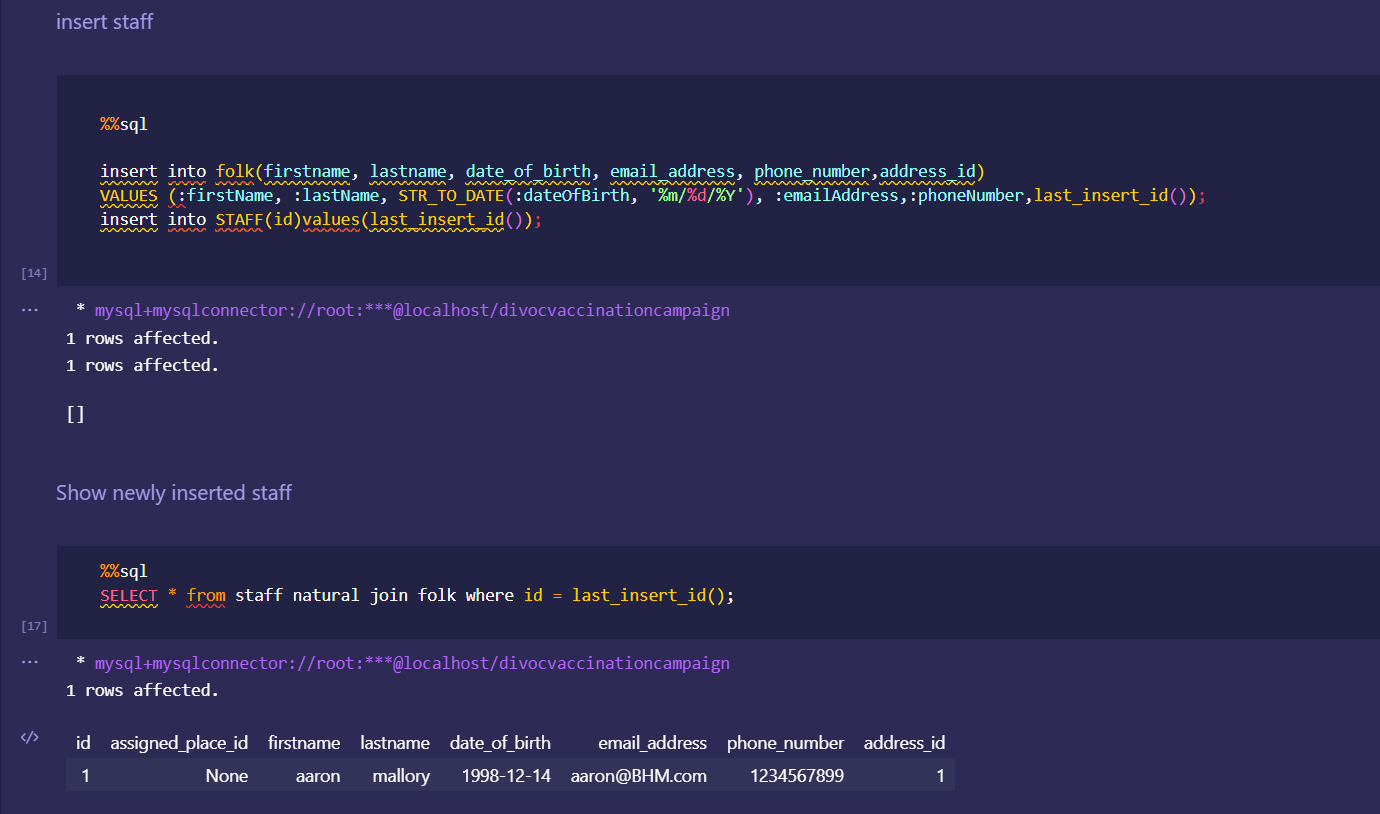
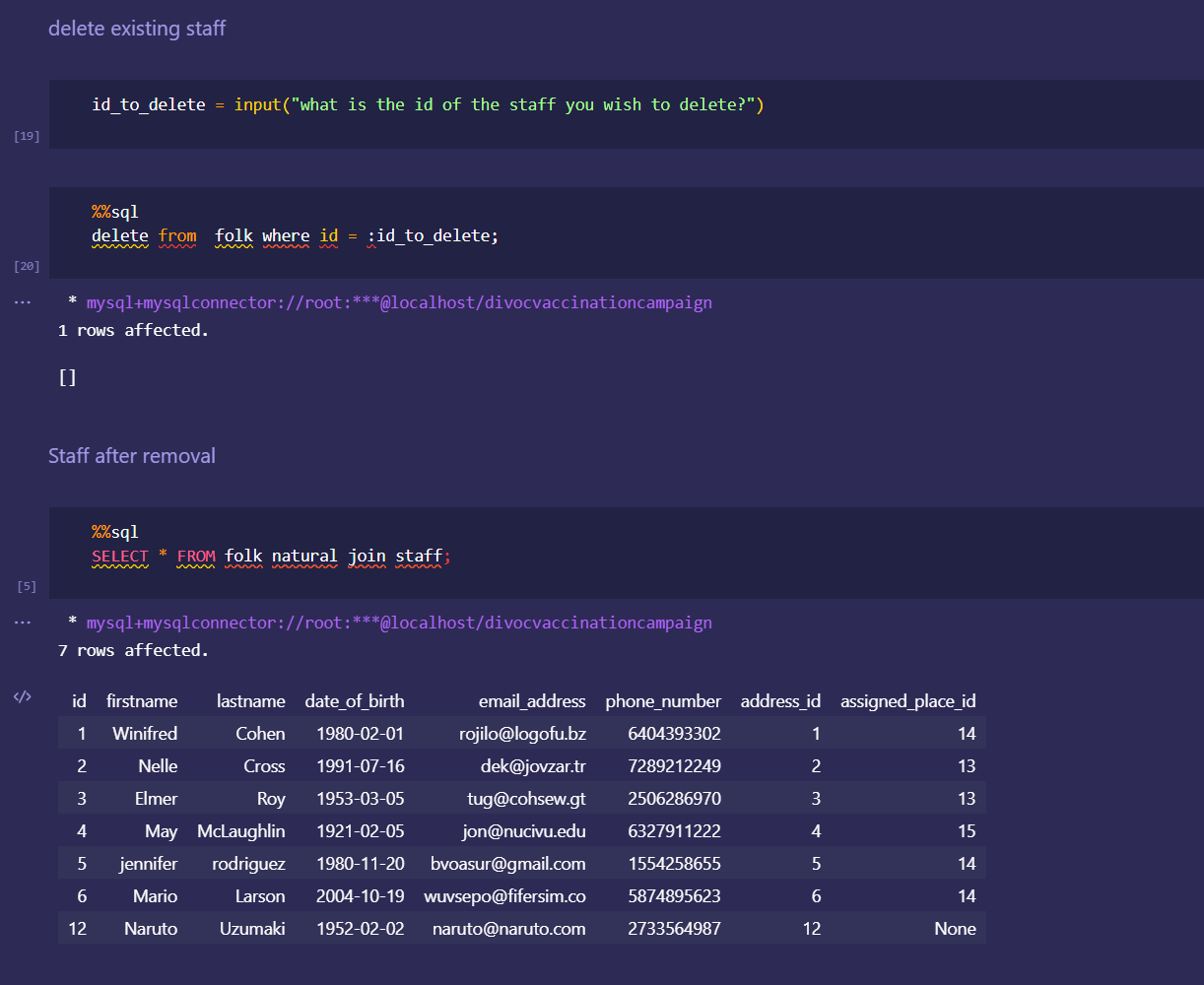
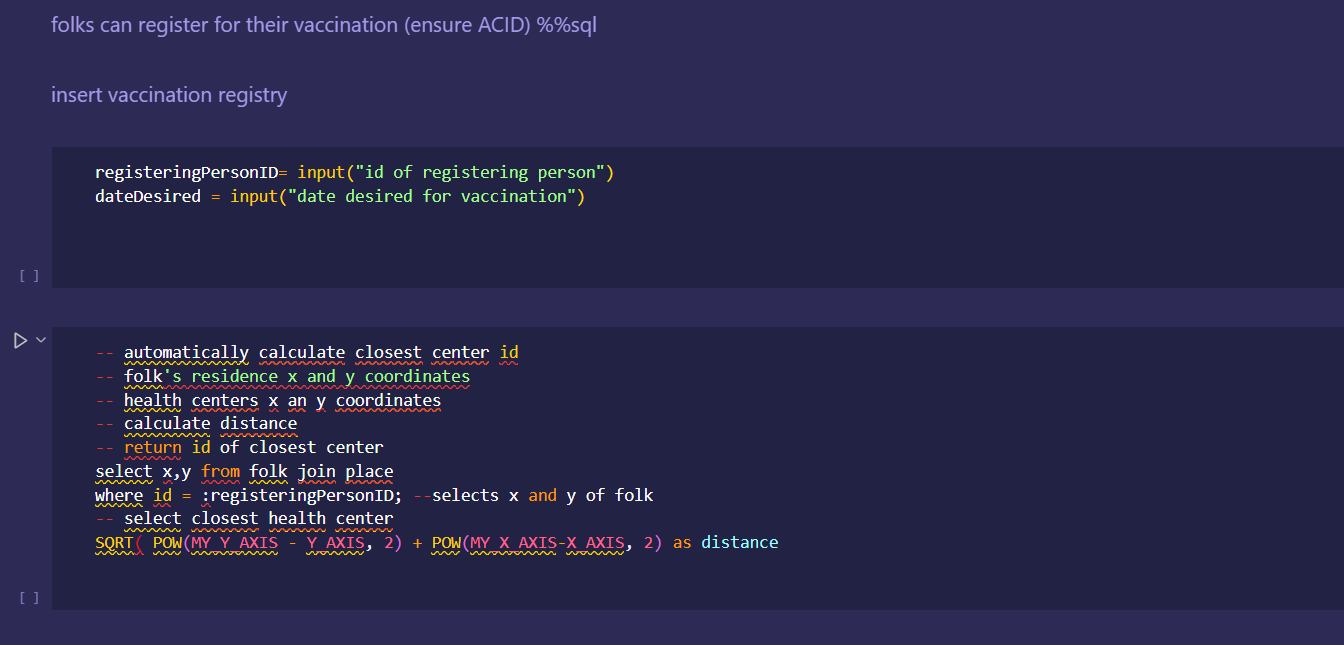
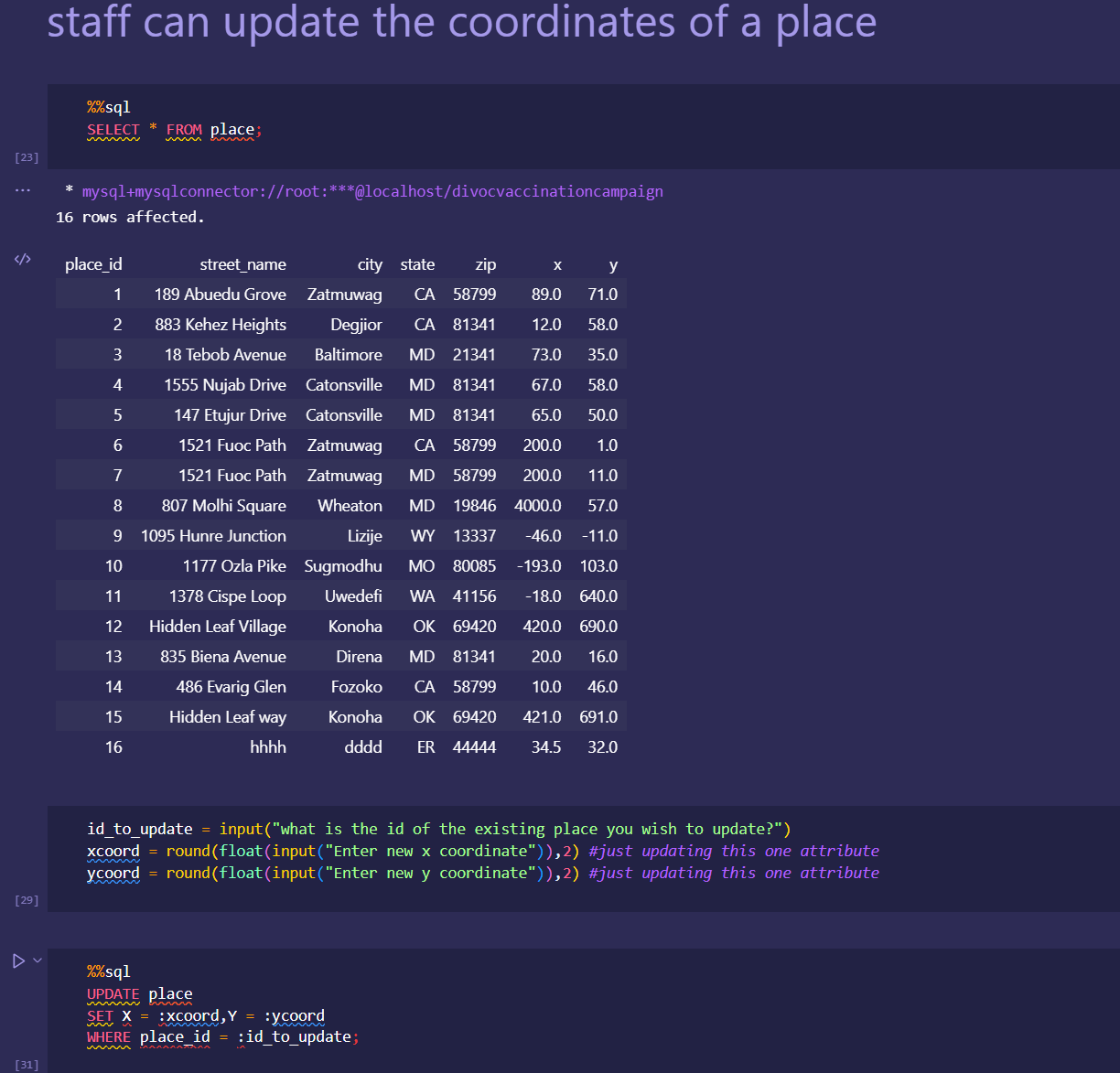
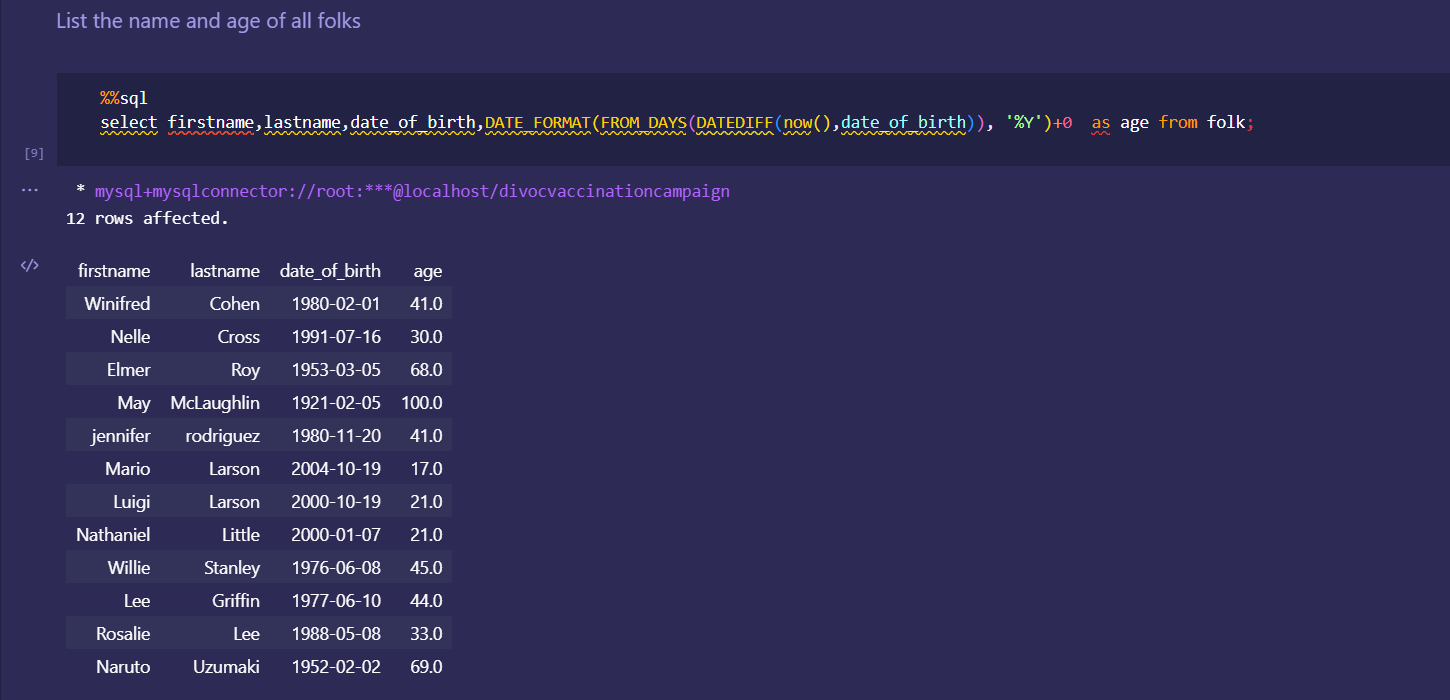
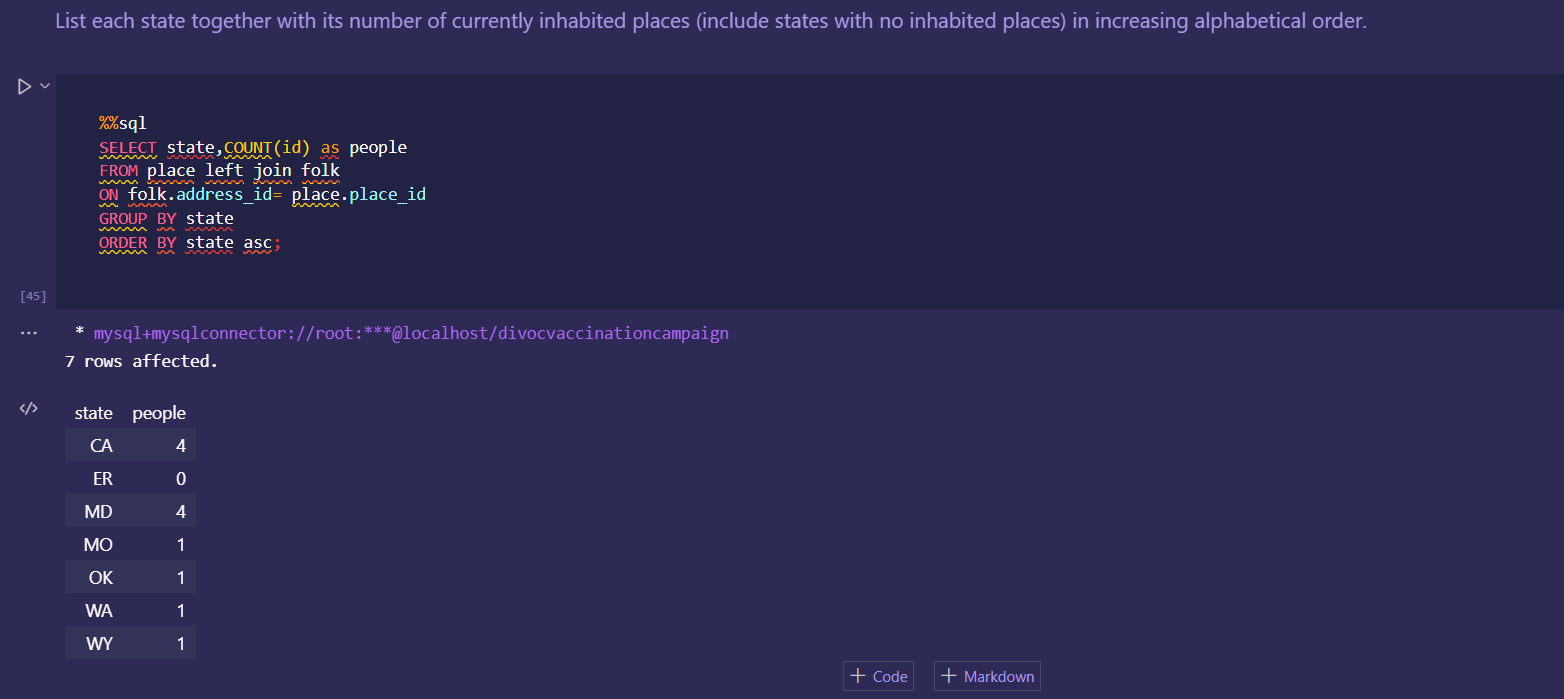
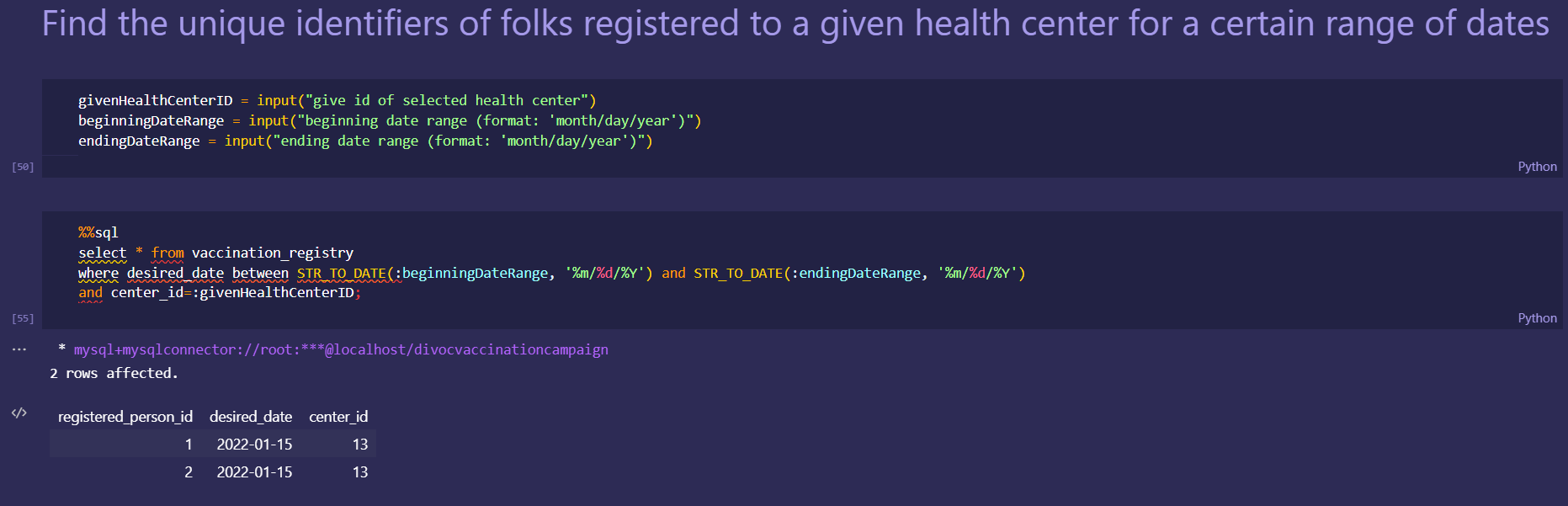
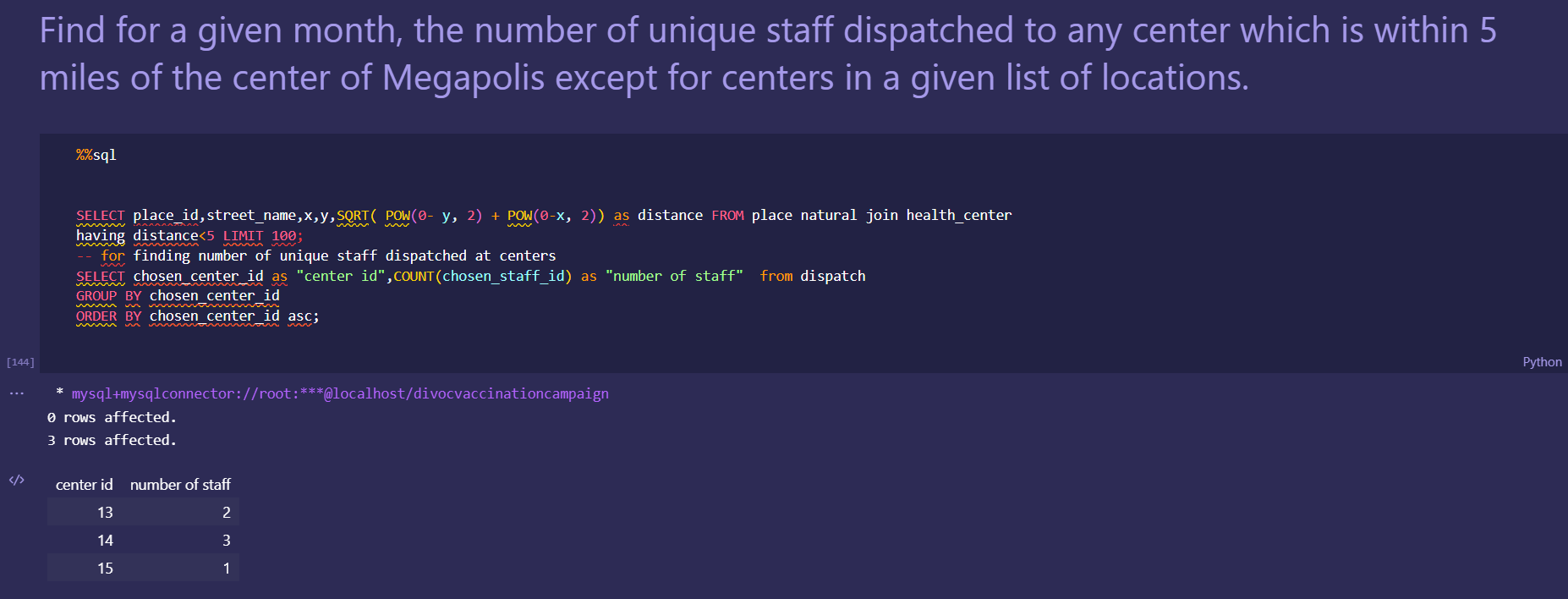
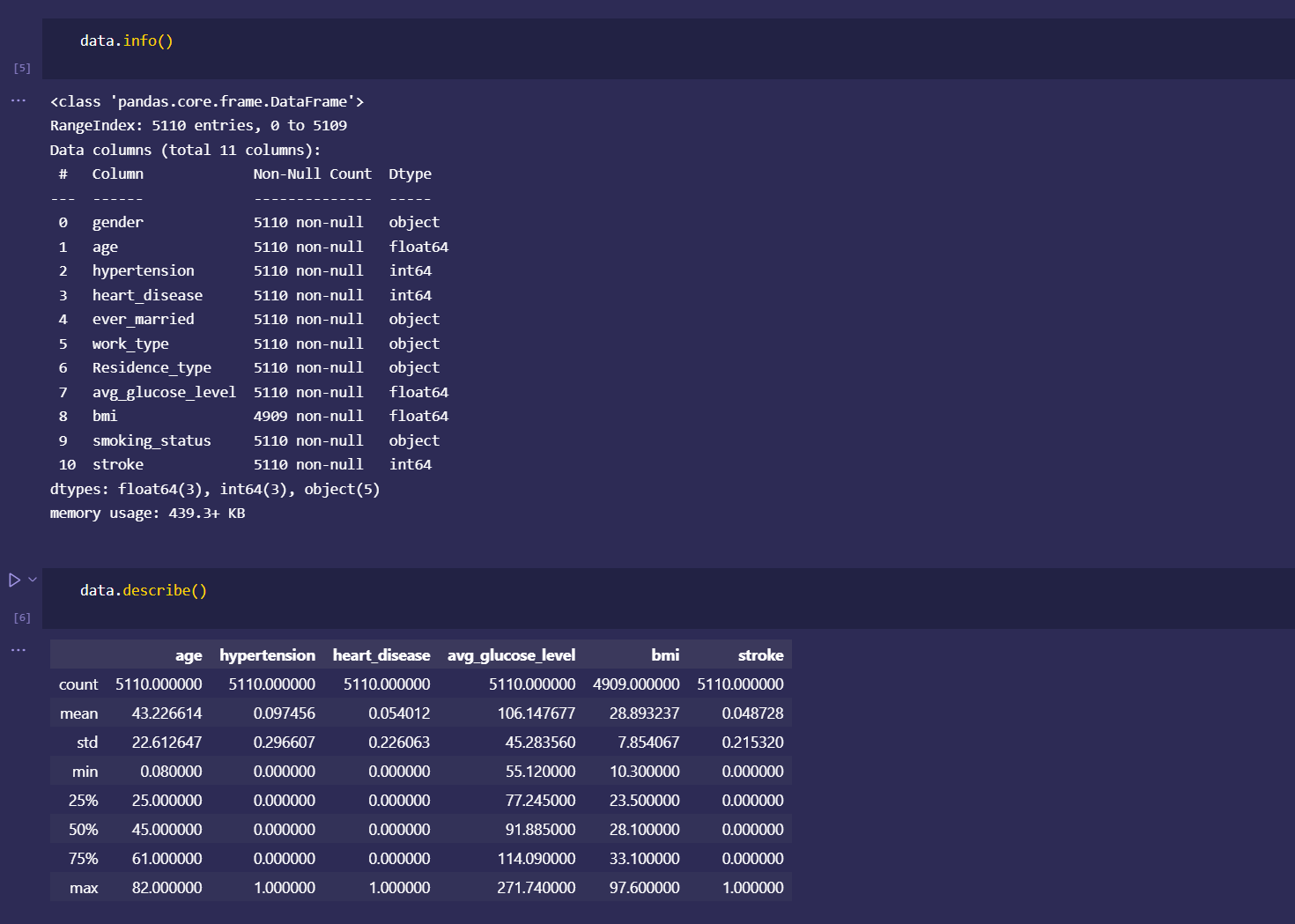
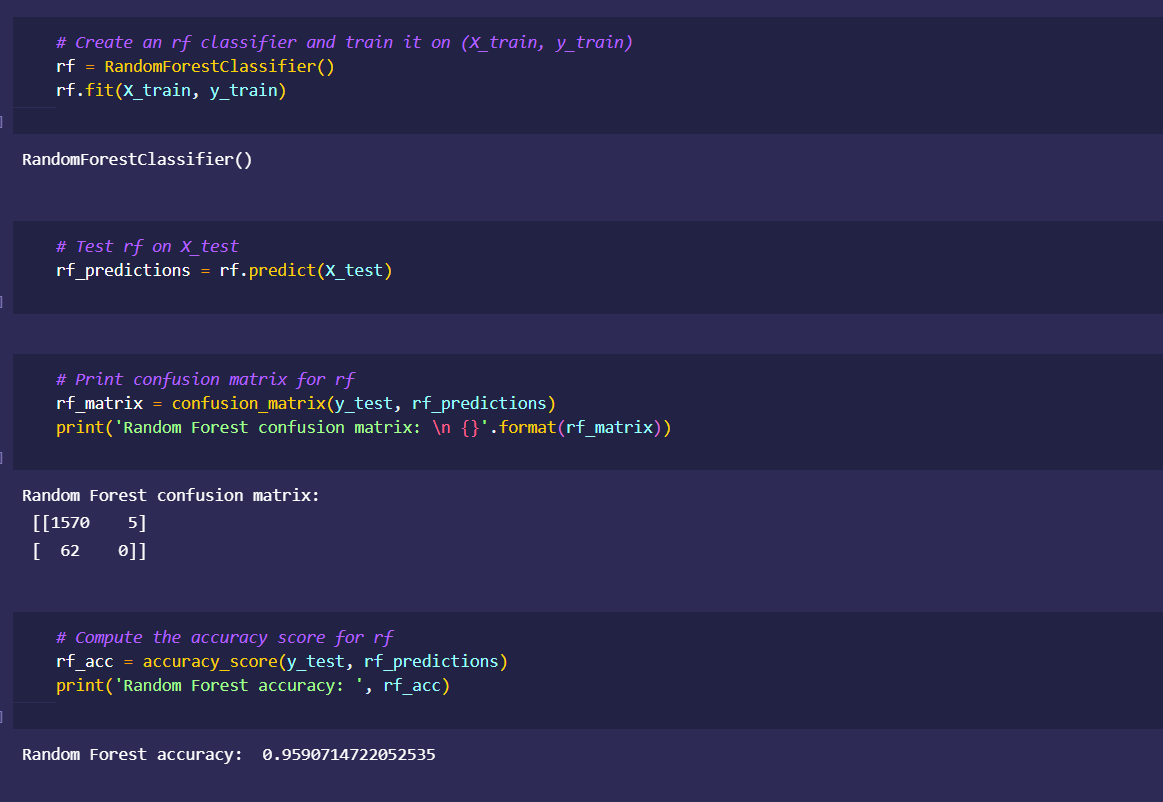
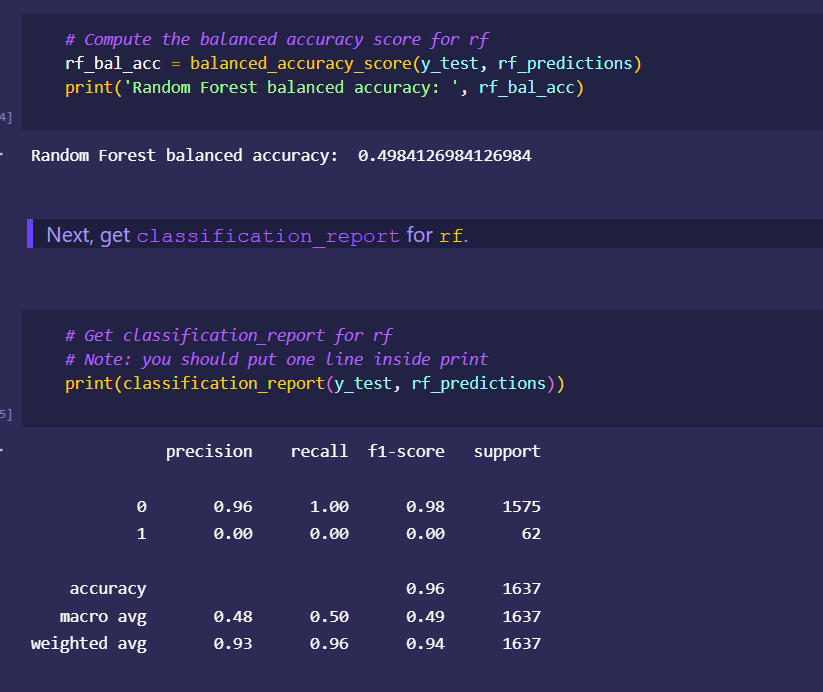
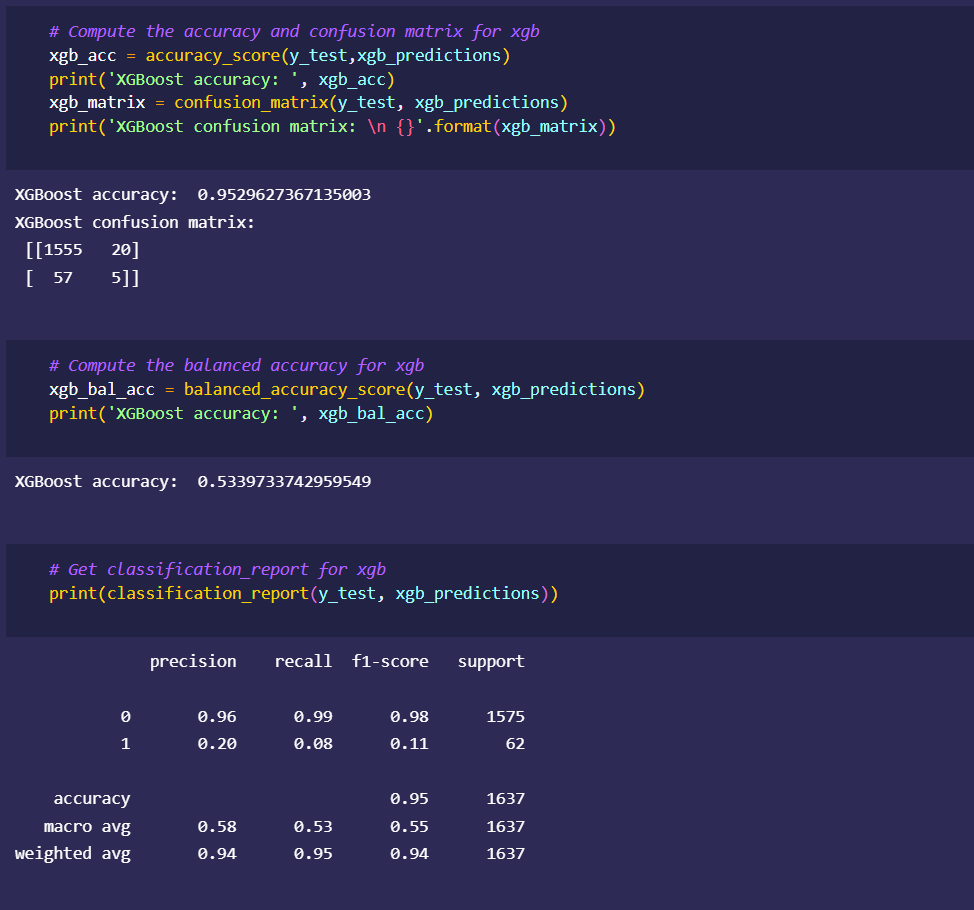
Japan 2021 Census PowerBI Dashboard
Analyzed publicly available data from Japan's official Government Statistics website
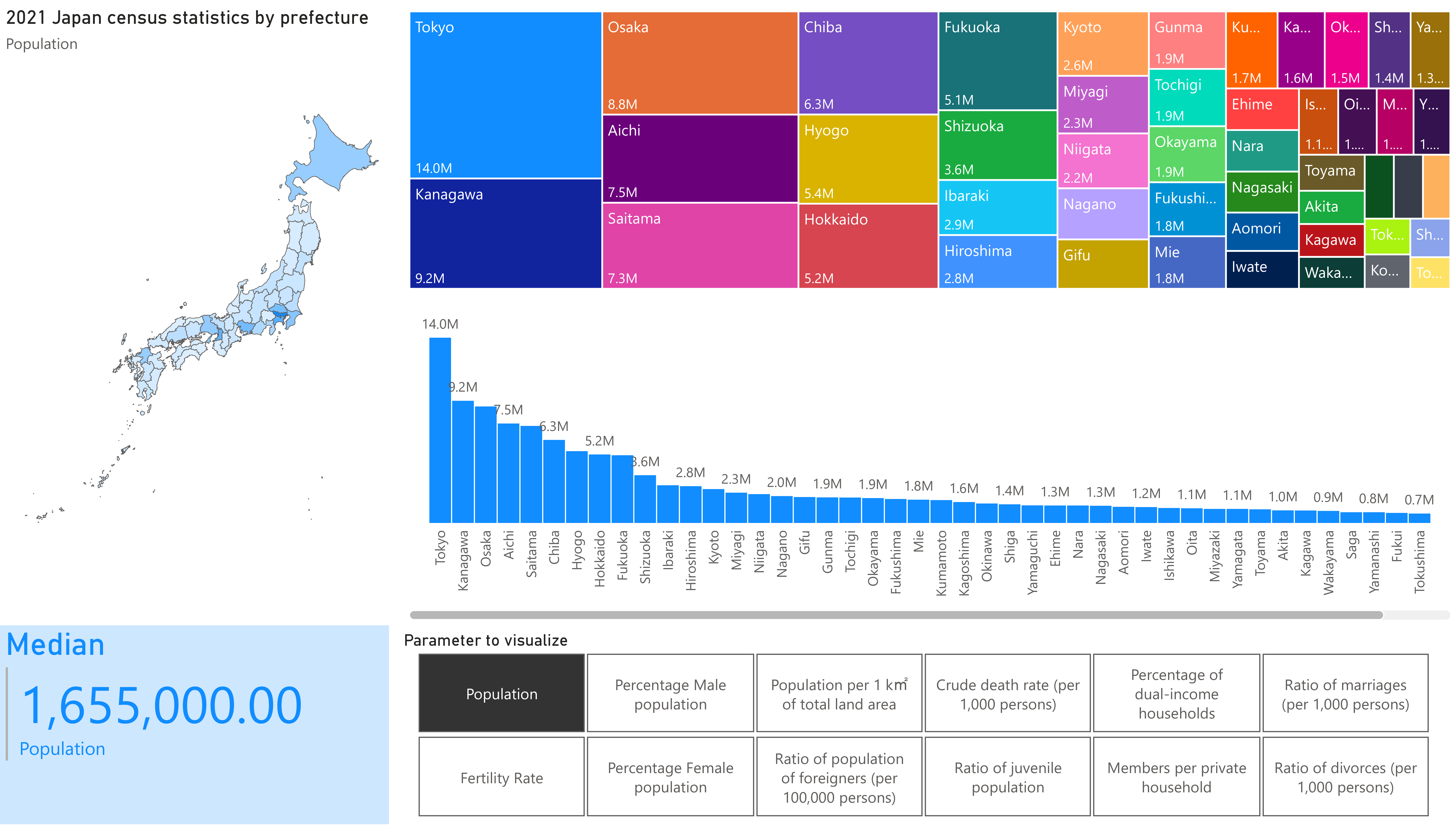
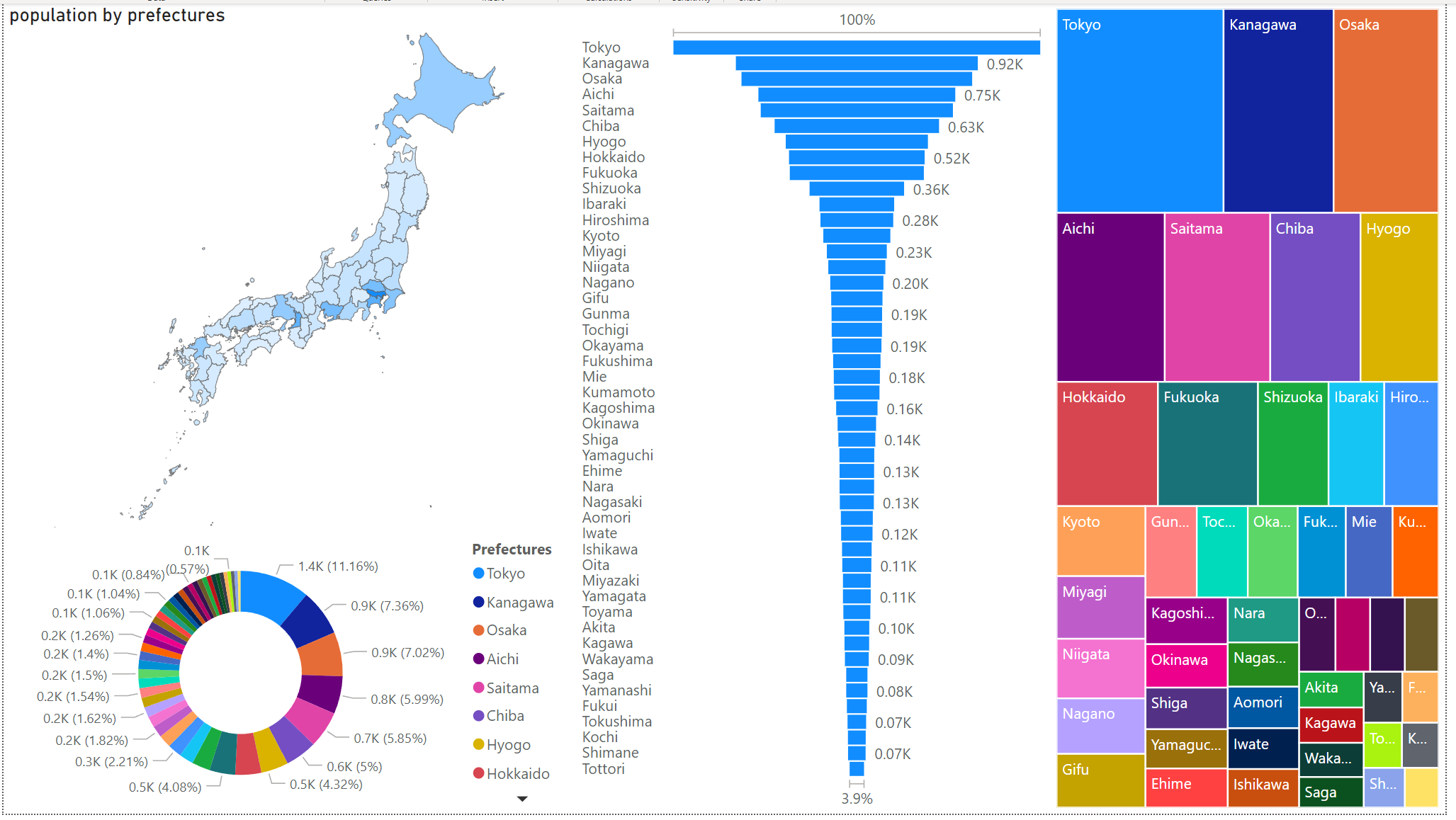

final dashboard (clickable link to fully view online)
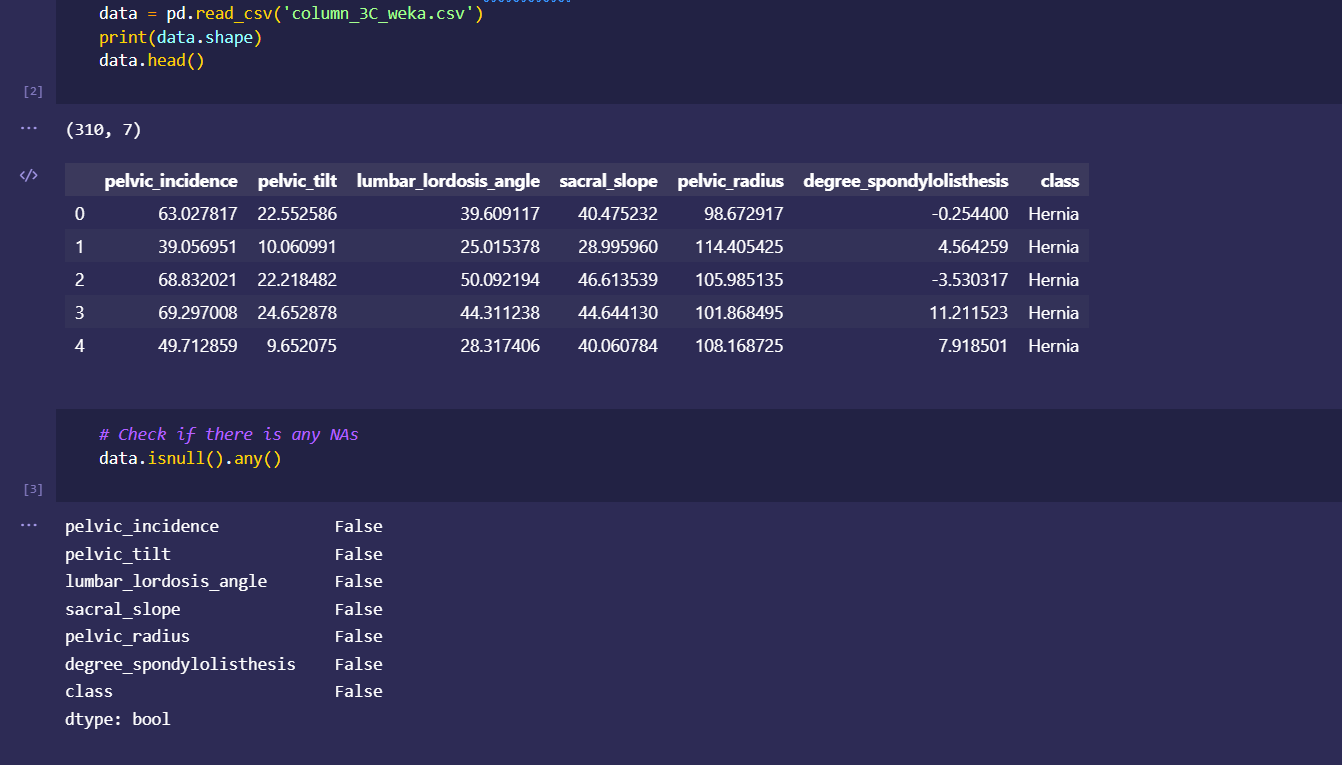
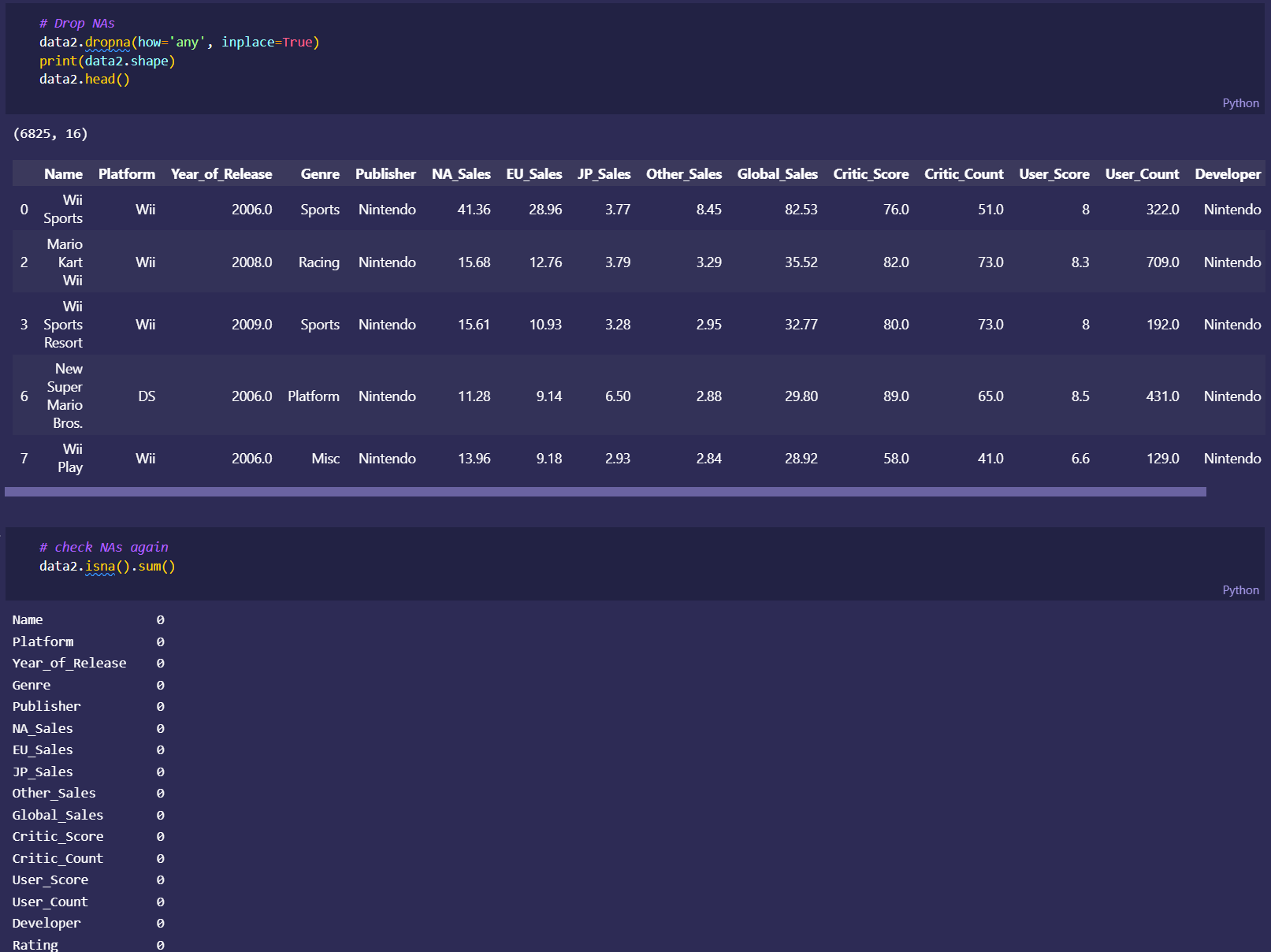
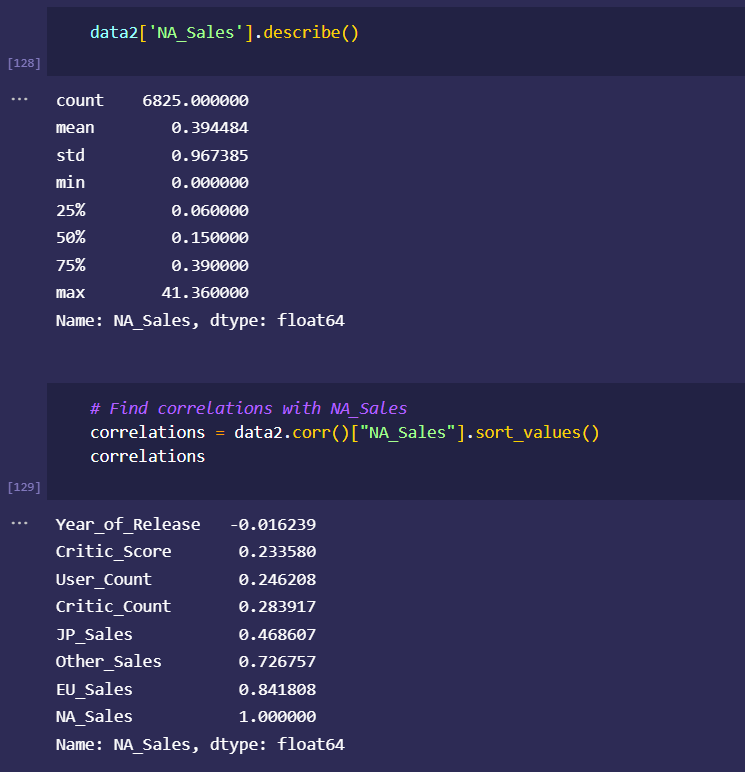
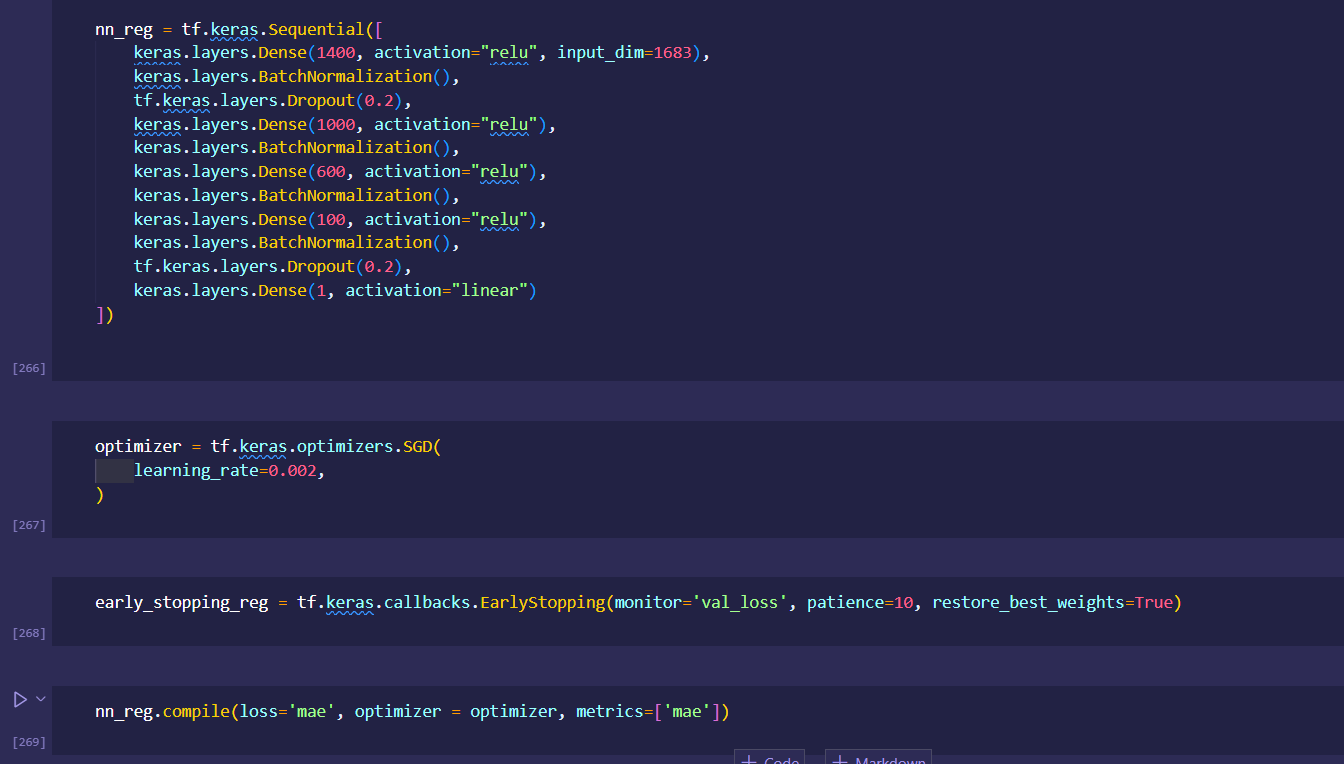
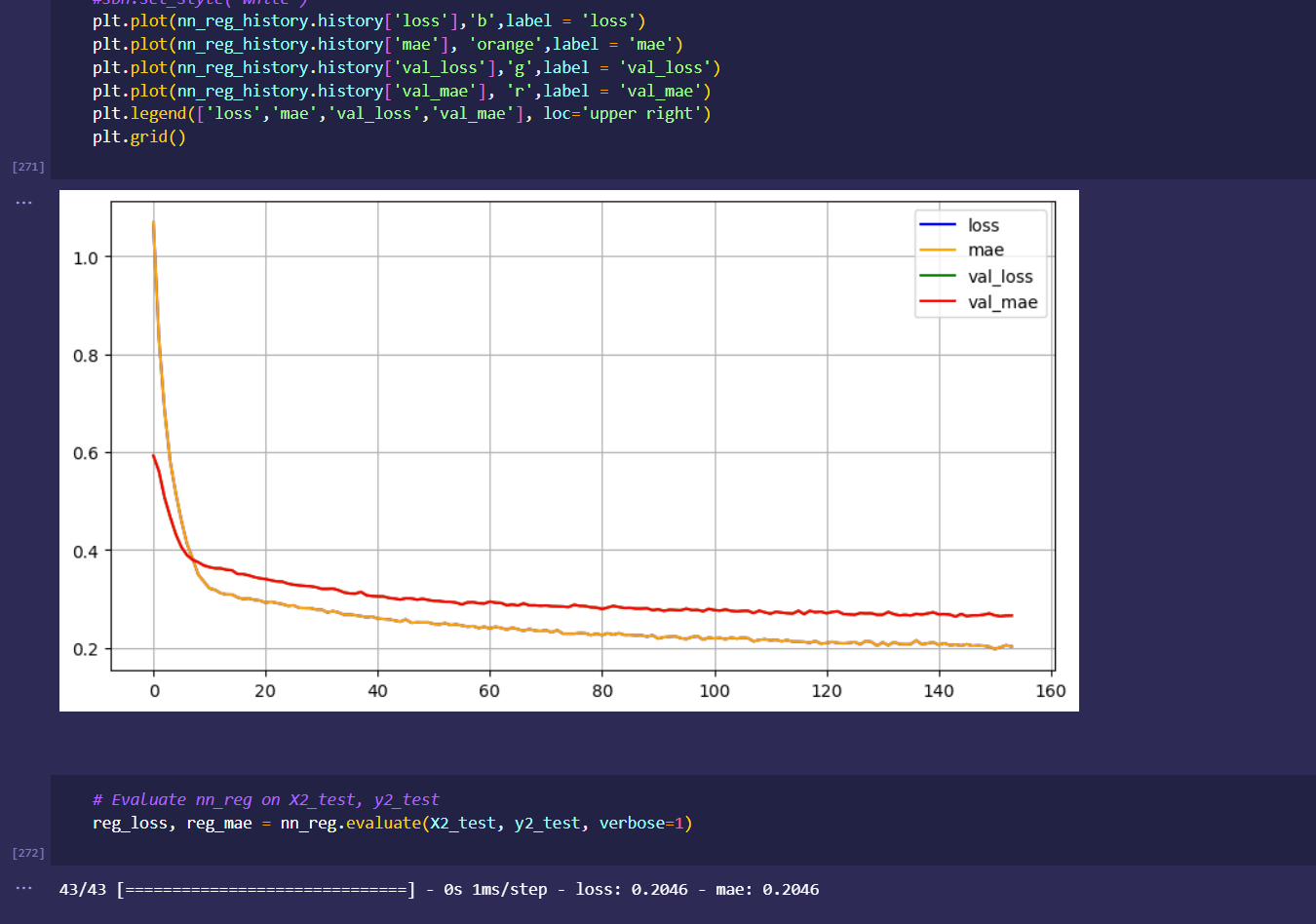
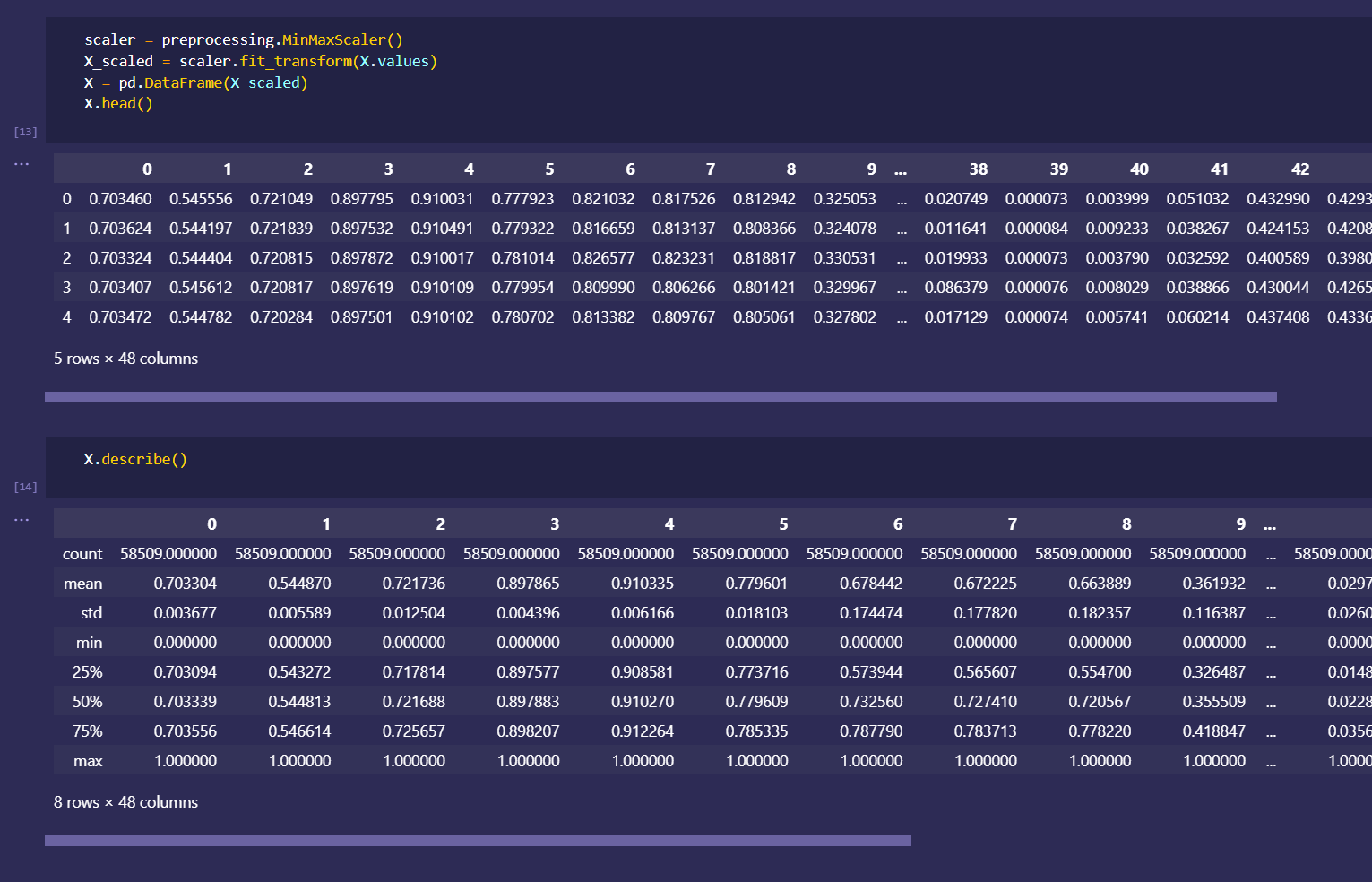
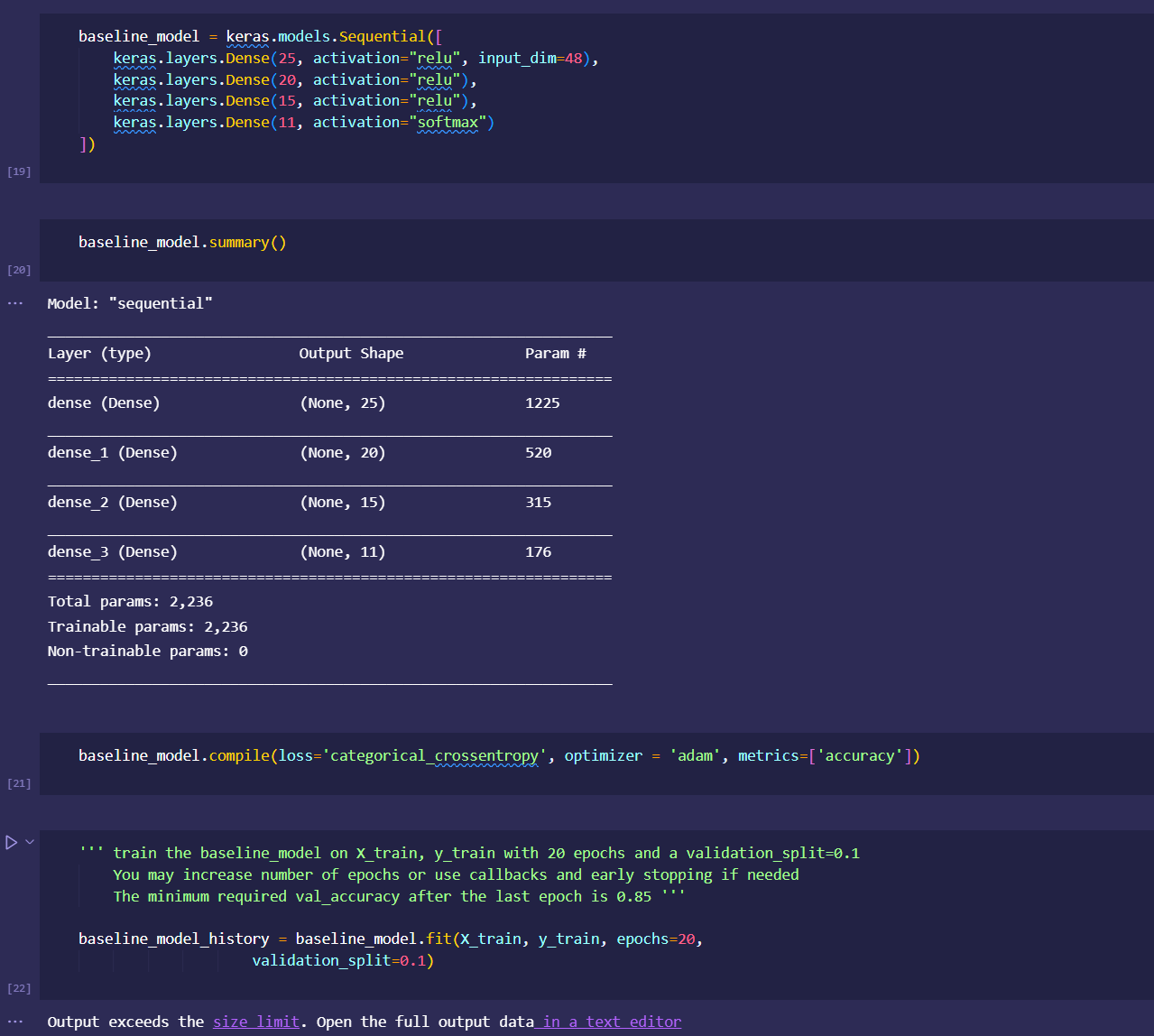
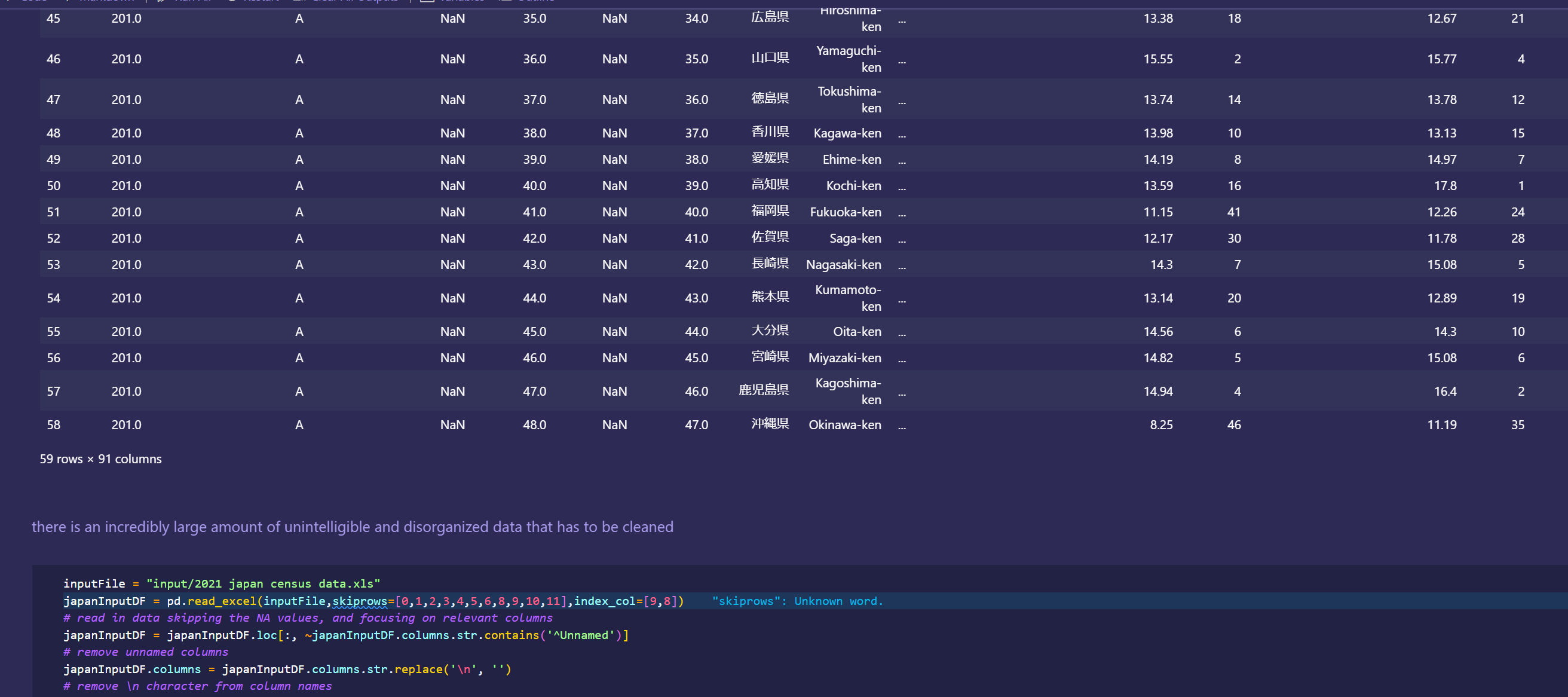
initial dataset preprocessing and cleaning (wrote python script/ jupyter notebook to do preliminary cleaning)
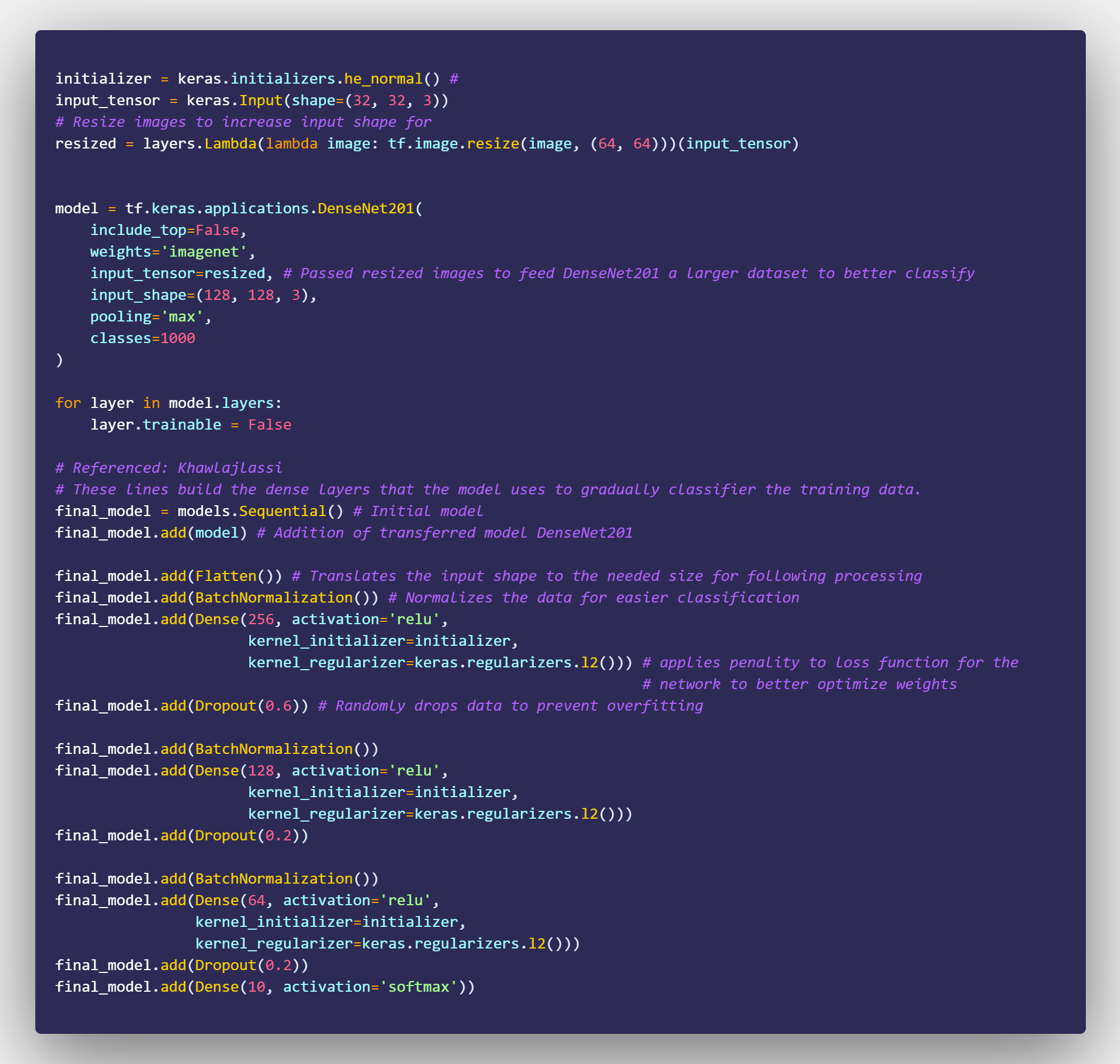
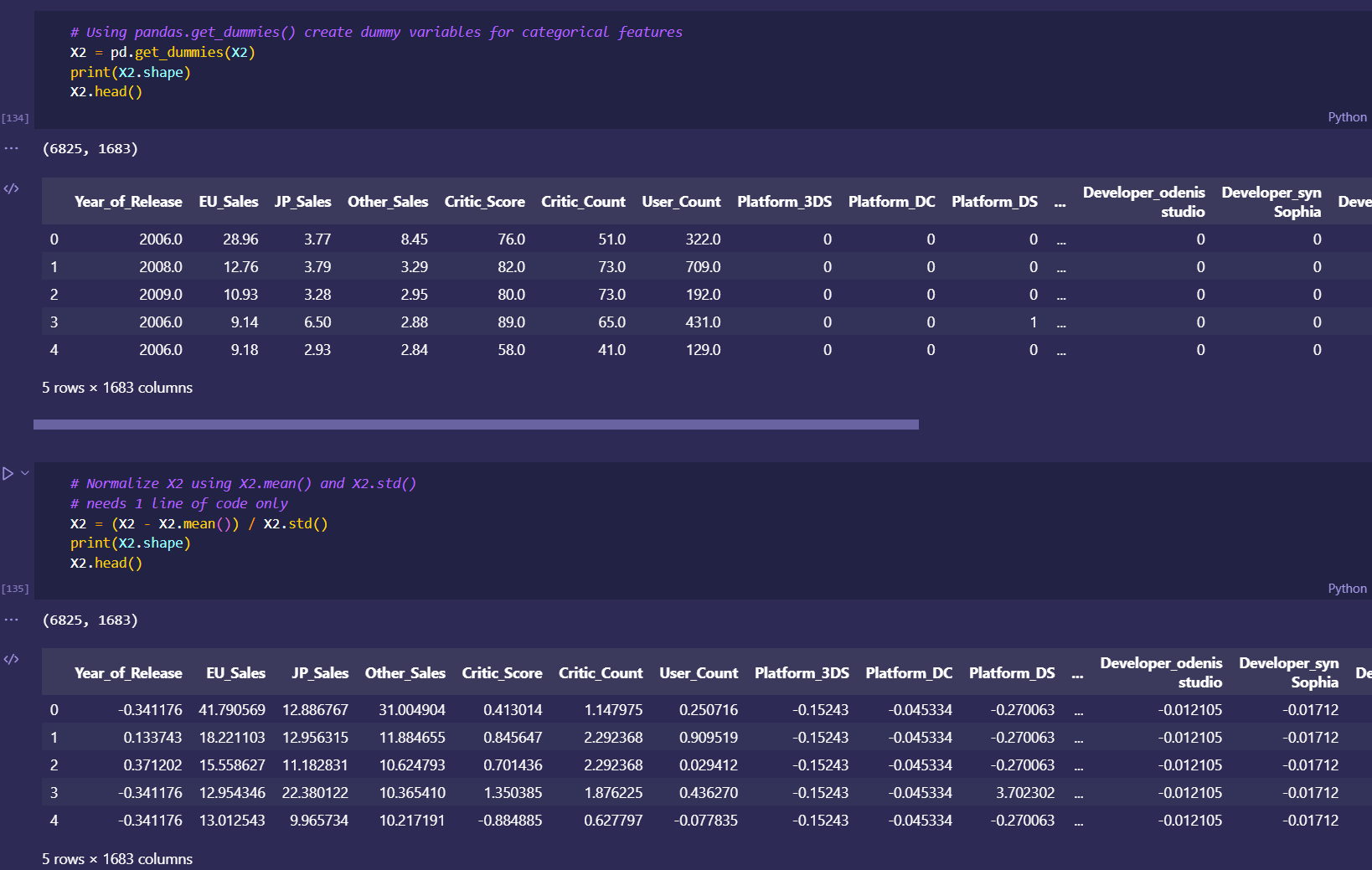
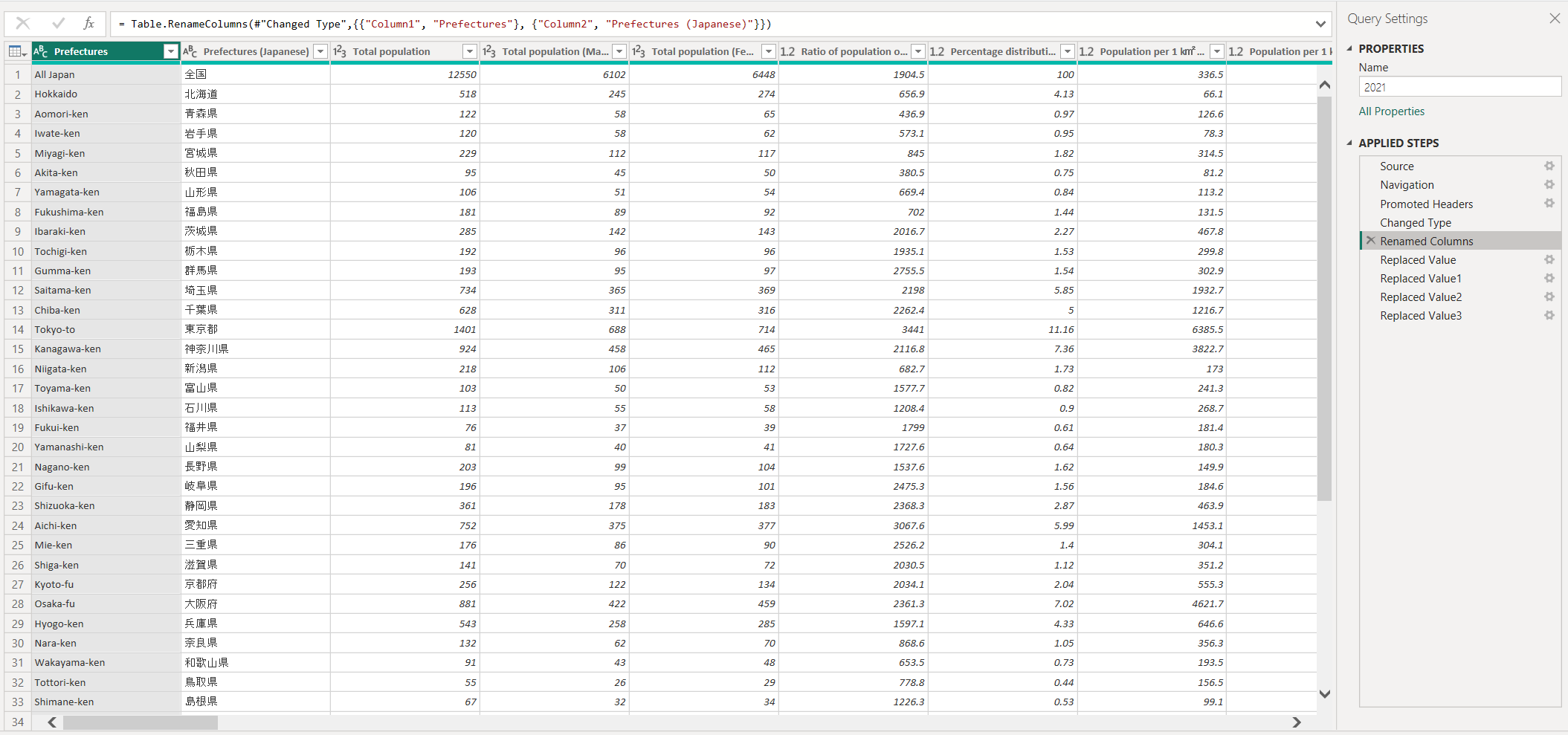
Secondary transformations and fixes done in PowerBI Query Editor
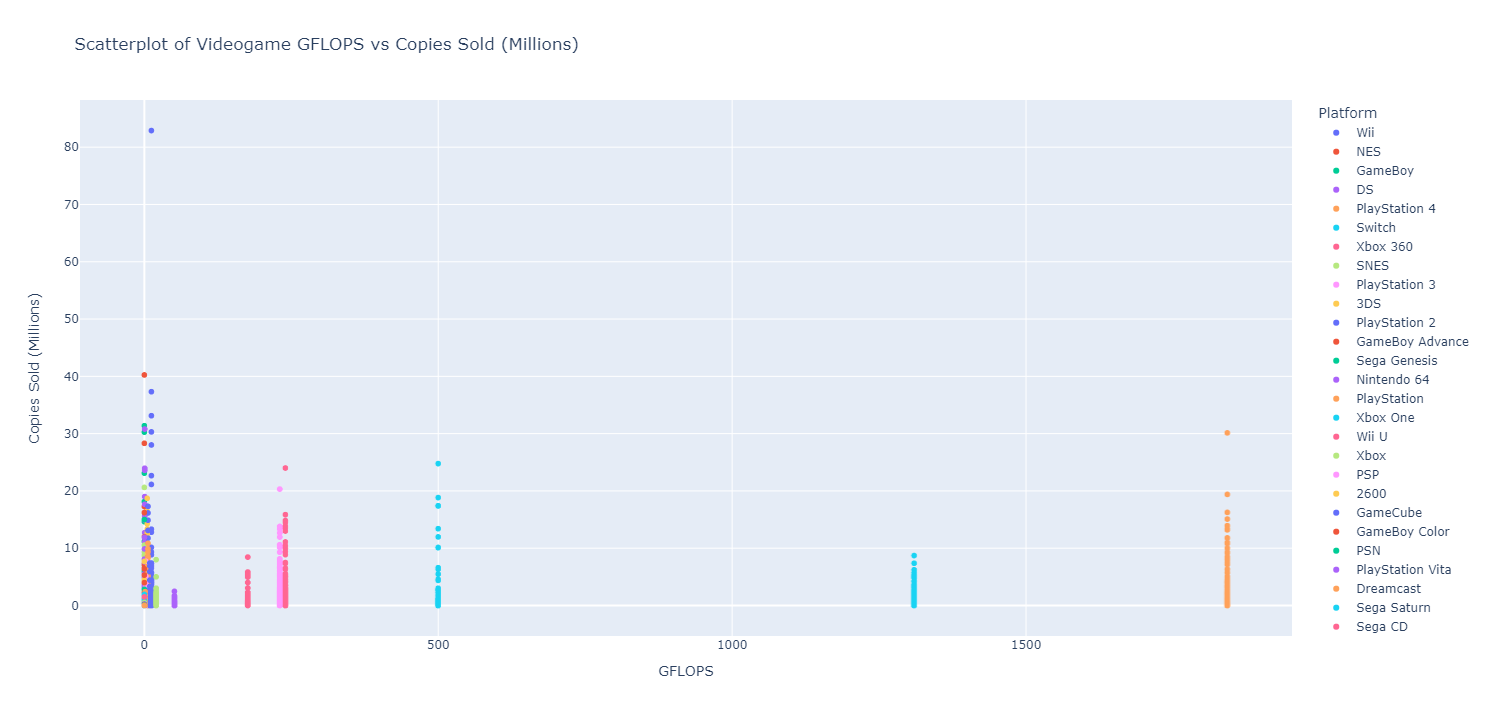
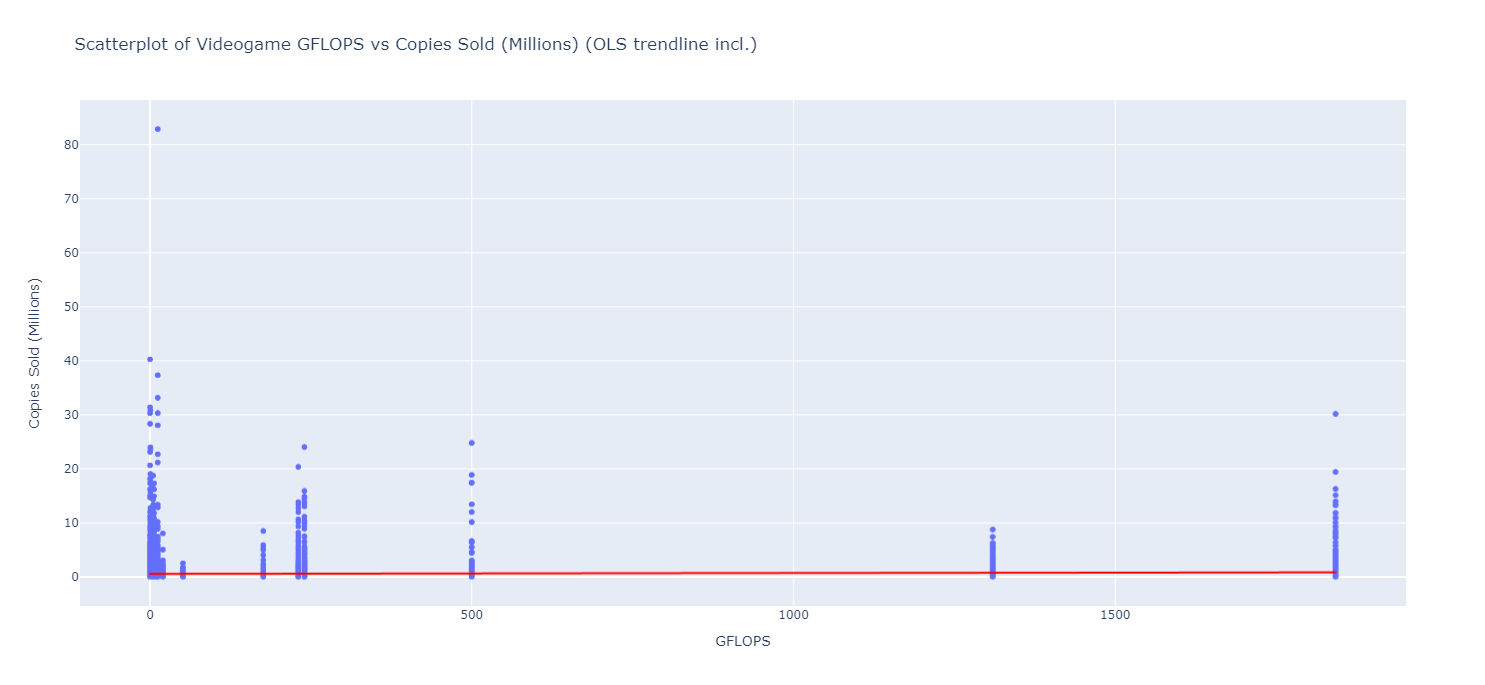
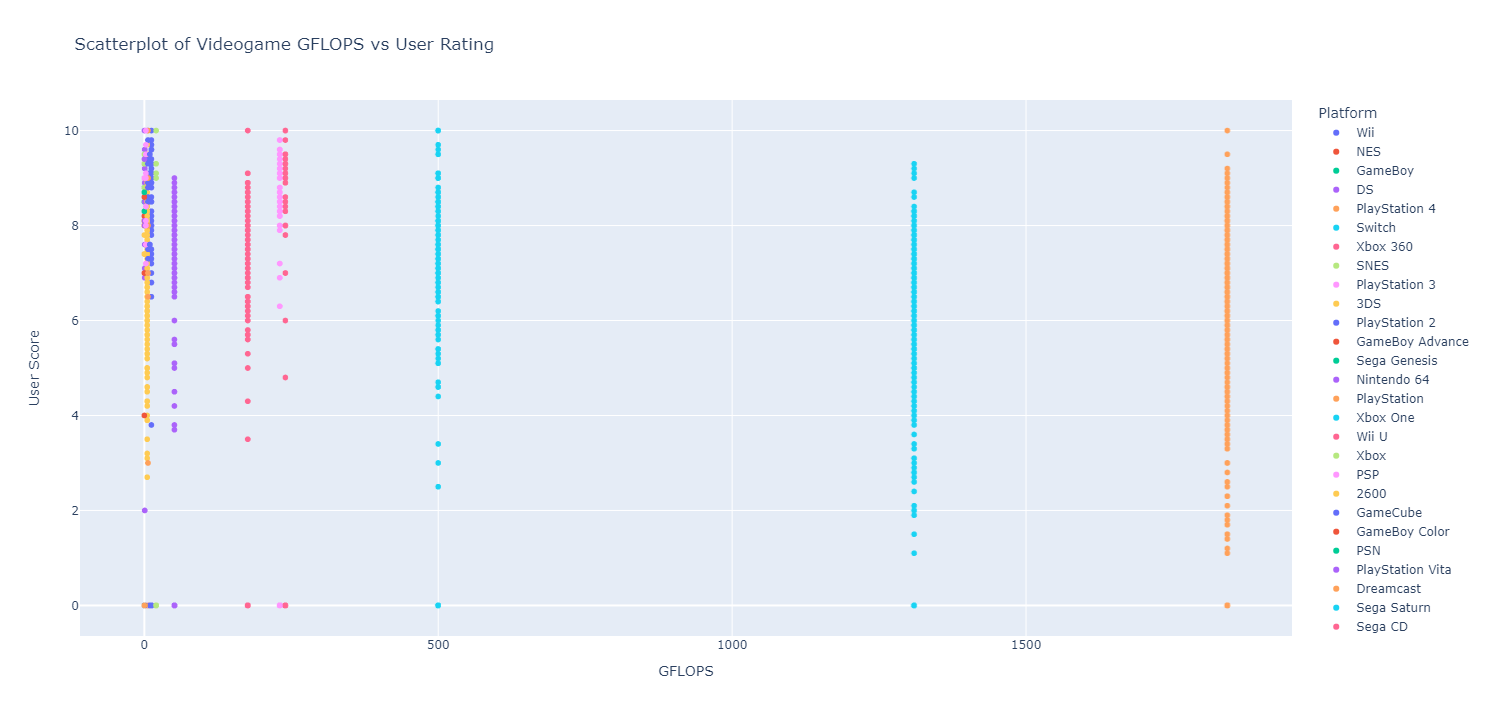
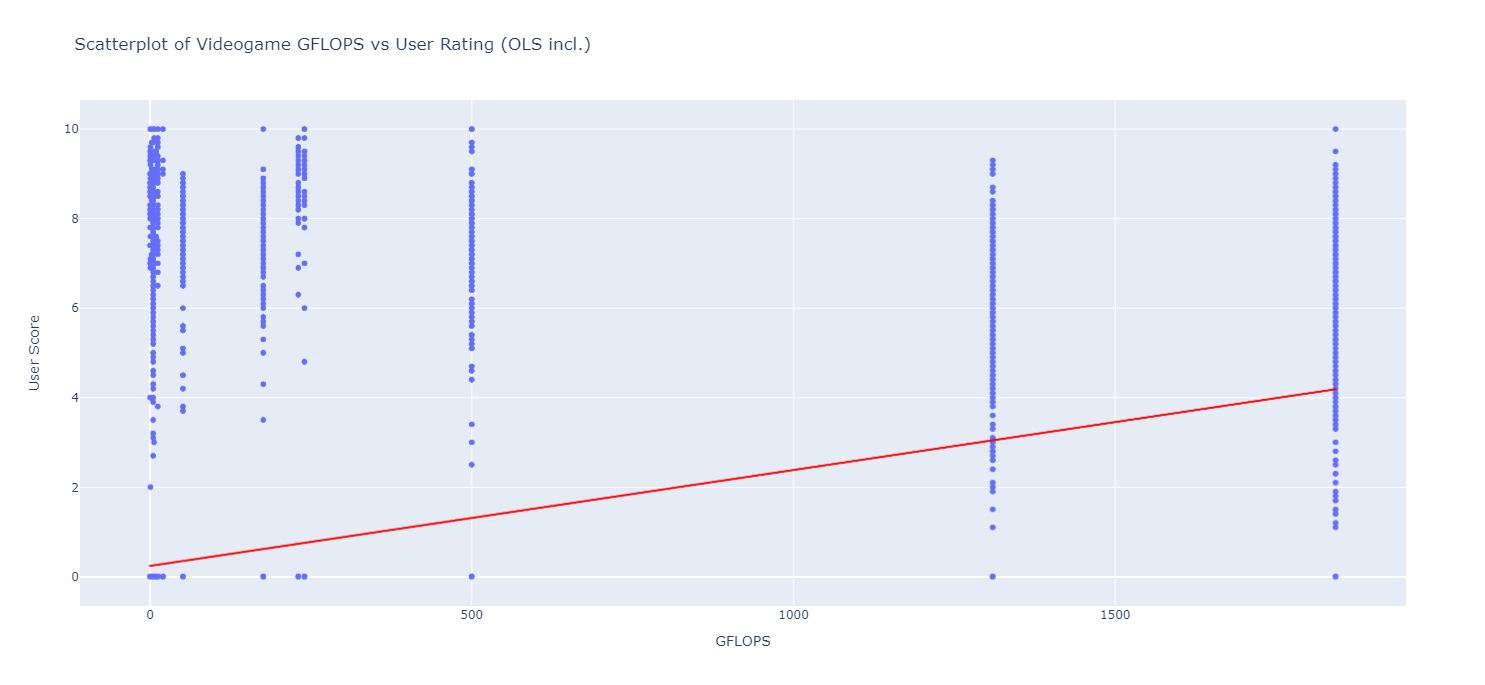
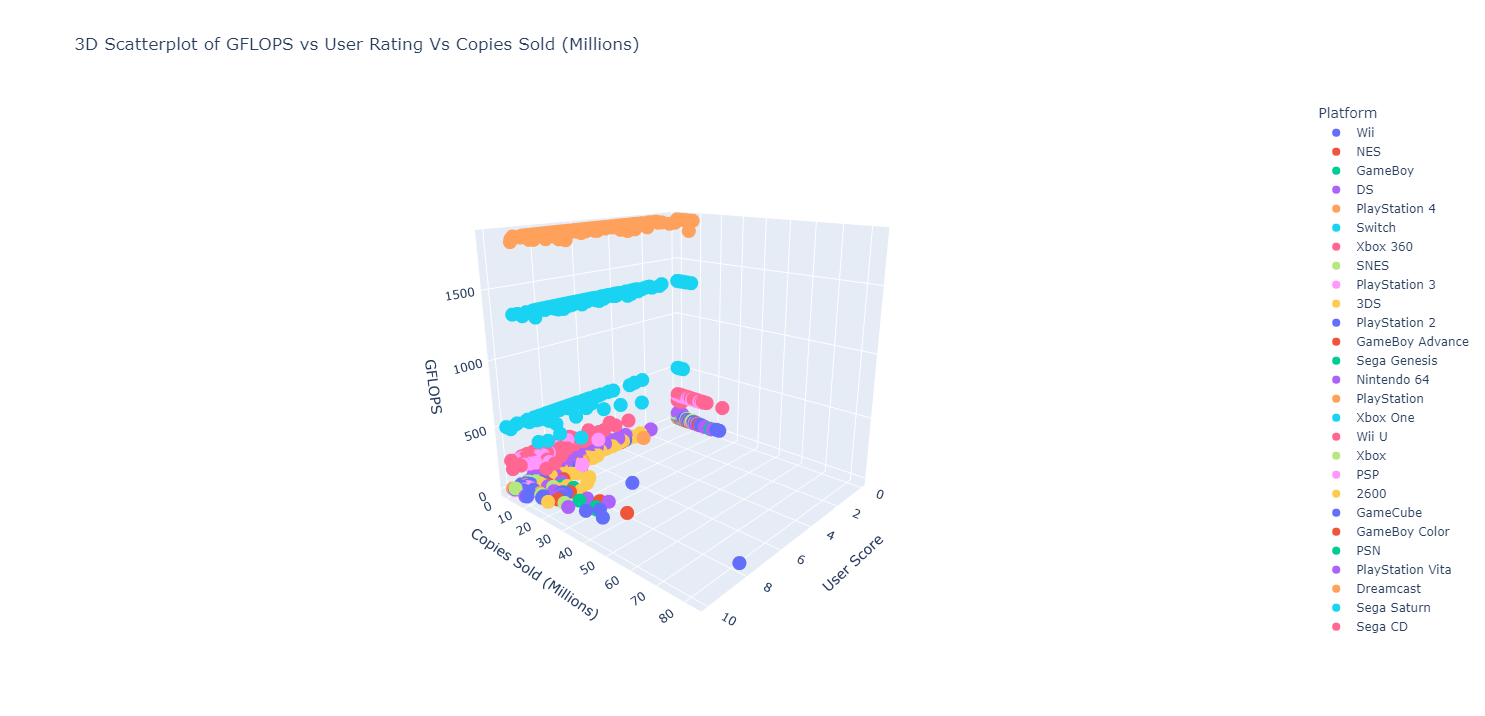
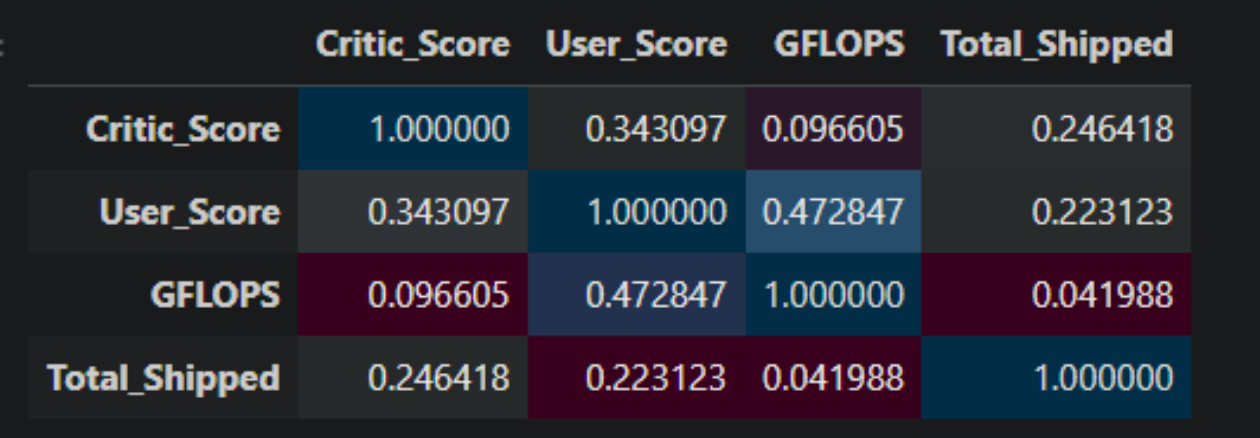
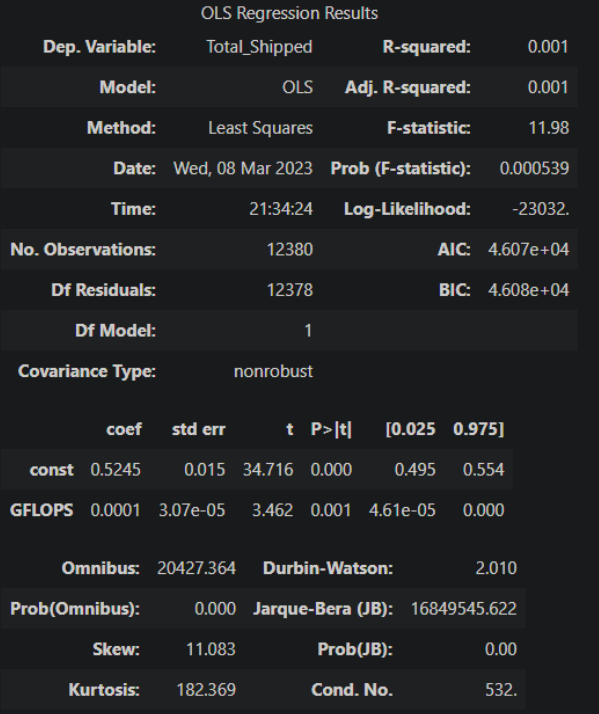
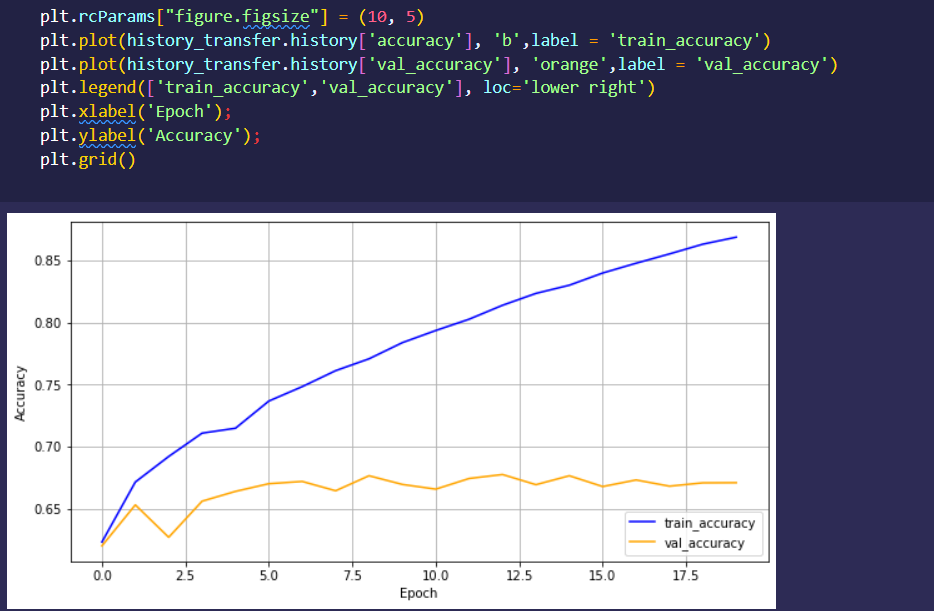
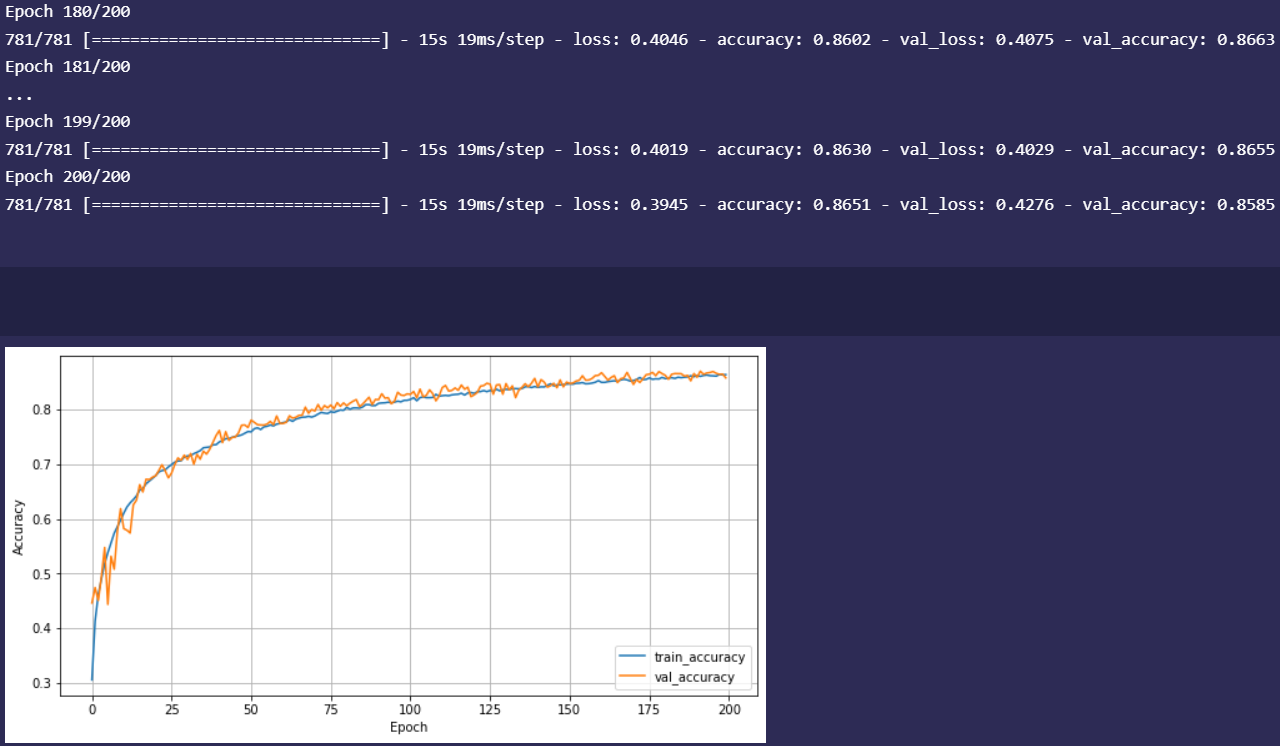
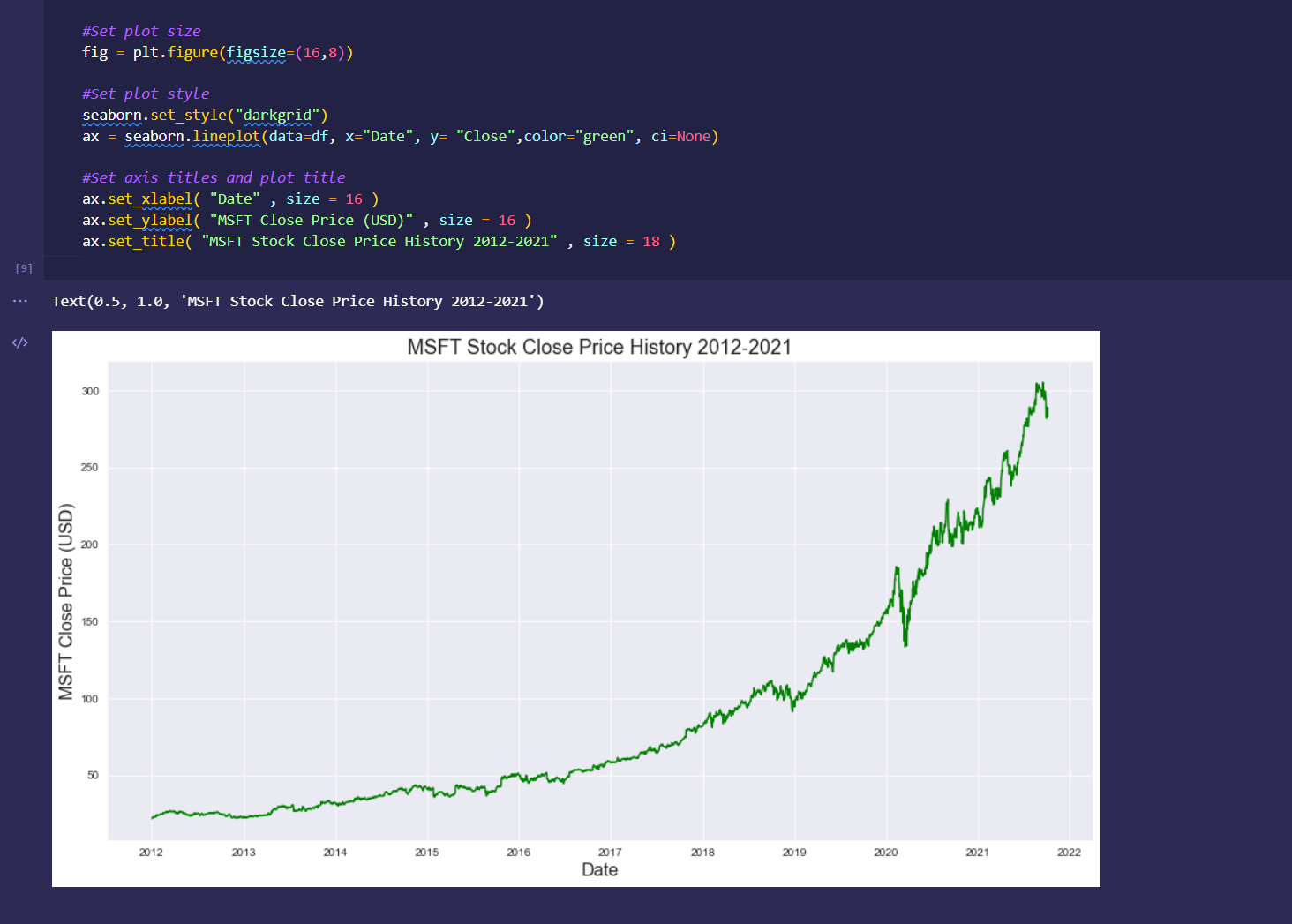
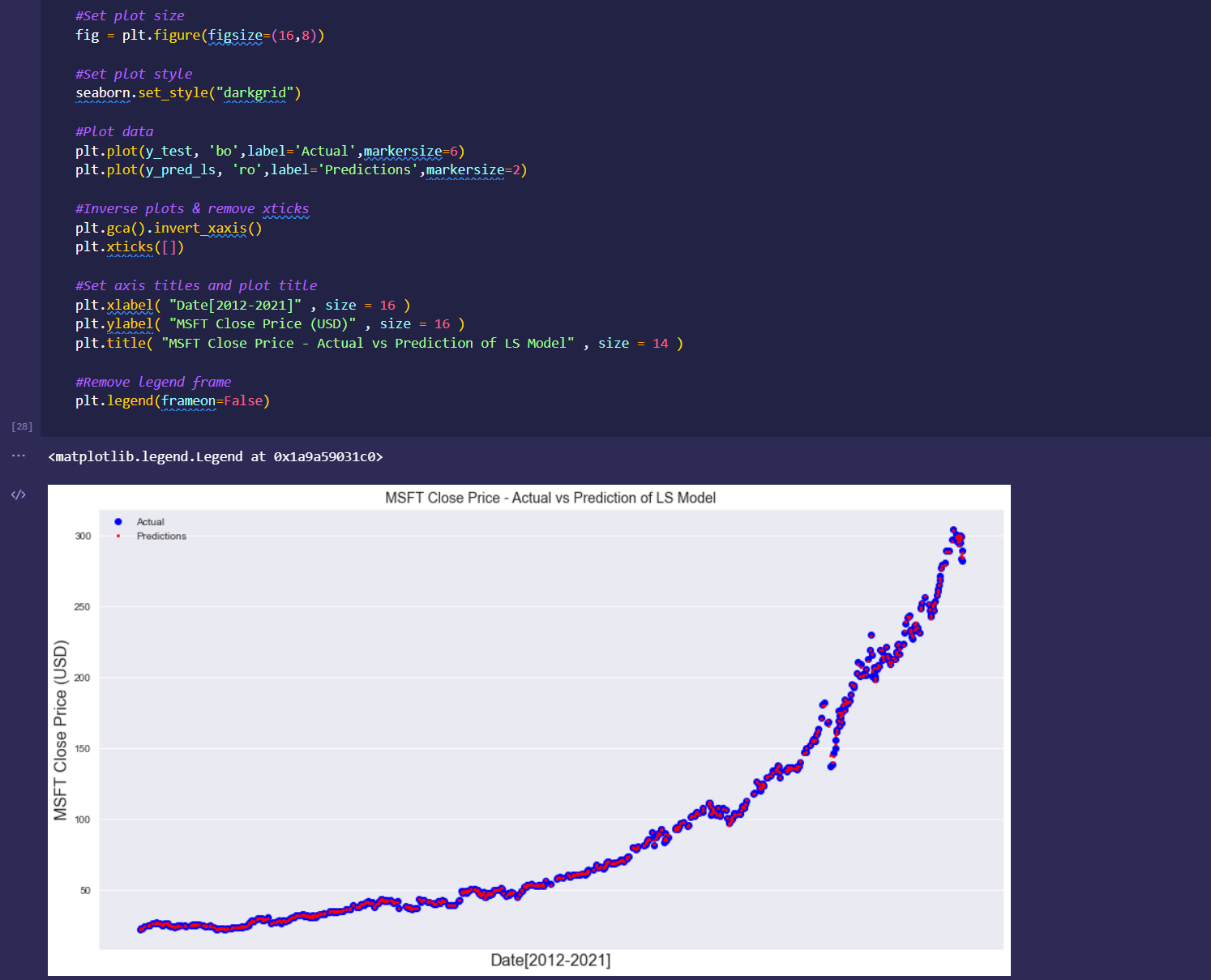
Rudimentary primary dashboard done based on population
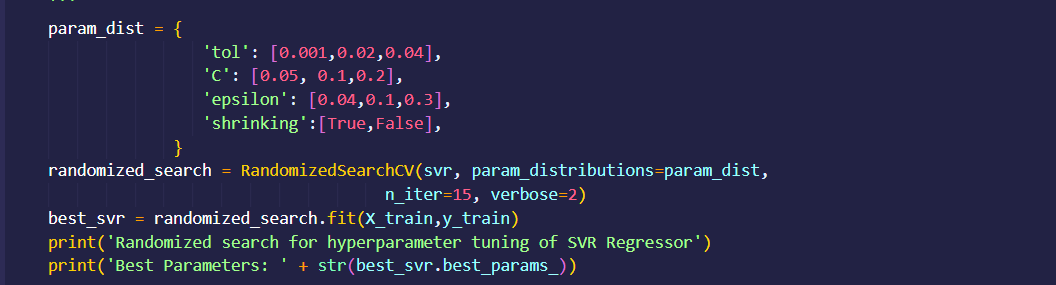
DAX used for field parameter selection in dashboard